
世界公共数据研究与报告白皮书

南柯舟本人
阅读后感谢援助:南柯舟矩阵因果关系分析引擎 ●数据来源:中国国家统计局、权威新闻媒体;版本说明:第九版。总体结论:根据 V9 的 54 项真实指标输出,中国问题不是“立刻断裂式危机”,而是…………请继续阅读…………
南柯舟矩阵因果关系分析引擎
数据来源:
国家统计局、权威新闻
版本说明:第九版,是语义口径审计、量纲擦除、支持力&压力正负向双通道、双向传导模式+堆垒理论迭代版
A. 总体结论
按 V9 结果,中国经济暴露出六个主要问题。
第一,财政融资压力上升,但中央显性债务率仍有缓冲。
第二,消费和收入仍有正向支撑,但居民部门没有形成强扩张。
第三,投资和房地产链条仍是最大实体拖累之一。
第四,民间信心和企业信心存在口径分裂,说明预期修复不均衡。
第五,价格链条不是主要危机,但价格指数口径仍需校正,低通胀和PPI弱势仍对应需求不足。
第六,货币和外汇提供托底,但货币到实体的传导效率只是中等,不能直接解释为强复苏。
这份 V9 版本的语义口径审计诊断报告展现出了极其清晰的 双通道传导特征 。在量纲擦除与跨变量关系能量(\tau_P, \tau_S)的系统性校准下,整体网络呈现出一种 “表面良性循环占优,但局部深层结构性断裂” 的非均衡动力学状态。
以下是对这份诊断报告的深度交叉解析与提炼:
一、 系统核心压力拓扑:宏观与微观的“双重叙事”
从全局指标来看,系统账面上的数据表现得相当乐观:
系统净收缩压力 为 -23.7127 ,且 阻滞点数量为 0 ,闭环状态判定为“正向良性循环占优”。
正向链指数(49.4757) 远高于 反向链指数(26.8483) ,货币流向实体传导分(49.8763)接近中枢。
⚠️ 核心矛盾点(深层断裂): 尽管全局判定为良性,但系统内部正在上演剧烈的微观不一致。
ENTREPRENEUR_CONFIDENCE_INDEX_2009_2025(已进行量纲擦除)的量纲擦除压力仅为 0.046 ,支持度接近 1.0 ,理论建议为“边界充裕,可适度扩张”。而与之对应的极值指标 ENTREPRENEUR_CONFIDENCE_MINMAX_2009_2025 与 PRIVATE_CONFIDENCE_INDEX_2009_2025(原始增长率体系)的压力密度飙升至 79.9528(高) ,收缩压力打满 100.0 !诊断建议直接触发警报: “结构性压力聚集,注意财政与流动性传导” 。
这表明,传统的平滑均值口径完全掩盖了极端区间(MinMax)中私营主体信心的局部崩塌。系统虽然没有全局阻滞,但压力正以极高的密度压在民营内生动力这一侧。
二、 传导链边际能量(Top Edges)特征分析
前十传导边的权重和效应(\tau_P=0, \tau_S=0, prior \ge 0.76)揭示了当前压力传导的底层路径:
1. 分配与治理压力对信心的反向对冲(Countercyclical Effect GINI_CHINA_2009_2025、CORRUPTION_INDEX 以及 WGI 治理指标,对 ENTREPRENEUR_CONFIDENCE_INDEX 的 net_weight 集中在 -0.61 \sim -0.70 之间。表明基尼系数(0.474)维持的高位震荡与治理感知,构成了对企业家信心的长期结构性“抽水”效应。
2. 货币与实体的非对称传导
M2_TRILLION 与 FX_POSITION_TOTAL 对 NOMINAL_GDP_DATA 的传导边显示了反周期压力释放(effect = pressure\_relief)。M2 的绝对量级(362万亿)虽然在量纲擦除后对收缩压力贡献了 84.2896 的高值(名义蓄水池巨大),但其扩张压力极低(7.9662),反映出货币虽然沉淀在账面上,但由于缺乏阻滞点,正通过政府信用(国债发行)和名义系统进行被动对冲。
三、 单指标多维压力矩阵对比
通过对具体量纲处理方式的拆解,可以清晰发现系统在不同类别下的冷热不均:
财政与债务
(Fiscal Debt) | CENTRAL_GOVERNMENT_BOND_ISSUANCE 中央安全边界极其充裕 。国债发行同比(70.54)虽高,但由于中央政府杠杆率处于量纲一体后的 27% 的绝对低位,扩张空间巨大,是目前系统最坚固的护城河。
价格与通胀
低通胀/通缩阴霾未散 。PPI 为 -1.8%,导致系统净收缩差为负,名义需求端极其疲软,印证了系统需要被动扩张的迫切性。
地产与投资
地产失血与结构重塑 。地产投资(-9.8%)与地产销售(-12.6%)收缩压力维持高位,但地产在系统中的份额占比(6.0%)已压缩至低位,系统正强行适应地产脱钩。
内需与民生
线下与线上的结构撕裂 。总消费增长(3.8%)尚可,但线下销售(OFFLINE_SALES)同比下降 -5.0%,净收缩差高达 +52.30,线下实体商业承压严重。
四、 战略诊断与传导闭环结论
基于 V9 语义口径审计的最终诊断:
1. “正向良性循环”的虚与实: 系统的安全边界是由 中央财政信用(低债务率) 和 货币绝对存量(高M2) 硬生生撑起来的。在总纲上,系统净收缩压力为负,允许政策层有充足的“容错率”和扩张筹码。
2. 传导压力的泄洪口: 反向链指数的压制力主要来源于 微观私营主体信心的冰封(MinMax 压力打满) 以及 线下实体消费的萎缩(-5.0%) 。汇率(7.08)对房地产板块虽有正向支撑效果(net\_weight = 0.2703),但由于外部关税指数(TARIFF_INDEX_WEIGHTED)的净收缩差高达 60.7388 ,外部需求的边际波动正在加大。
3. 最终建议路径: 必须利用中央政府债务发行(CENTRAL_GOVERNMENT_BOND_ISSUANCE)的绝对充裕空间,越过已被阻滞的常规信用传导链条, 直达民生驱动力与企业家极值信心对冲端 。擦除量纲后的系统表明,若继续沿用大水漫灌式的传统货币传导(M2 到 GDP),只会加剧蓄水池内部的“堆垒迭代密度”,而无法有效修复私营部门的 MinMax 崩溃区间。
最终结论是:V9 数据透露出的中国问题不是“全面失控”,而是“托底能力尚在、结构性阻滞尚未解除”。中国经济还能维持正向循环表象,但这个循环并不舒展;最危险的不是单一总量指标下跌,而是投资、地产、民间信心、财政融资和分配结构这些慢变量互相叠加,压低长期内生增长能力。
根据 V9 的 54 项真实指标输出,中国问题不是“立刻断裂式危机”,而是“表面正向循环恢复、内部结构压力仍重”的状态。V9 给出的总判断是“正向良性传导主导”,系统收缩压力 28.1578,扩张压力 51.8705,净收缩压力 -23.7127,说明模型在语义口径修正后认为扩张支持力明显大于收缩力;但跨变量关系能量只有 0.01110835,说明这种正向传导的共振强度并不高,更像“弱修复”而不是“强复苏”。
真正透露出的问题是:中国经济的总量支撑仍在,但支撑来源并不均衡。货币、财政空间、部分治理修正、价格温和、外汇和总量 GDP 指标给系统提供托底;但投资、地产、民间信心、销售、财政融资、外部关税和部分价格口径变量仍在释放结构压力。
真实 54 指标下,V8 的结论应读作:真实 54 指标下,V8 的结论应读作:系统整体不是强扩张,也不是强收缩,而是总量涨缩压力接近平衡,但存在上游结构阻滞。系统收缩压力为 44.0814,扩张压力为 43.1119,净收缩压力仅为 0.9695,说明收缩力与扩张力在总量层面基本对冲。正向链指数为 35.217,低于反向链指数 46.0641,说明反向压力传导略强于正向支持传导,尤其需要关注的“政治结构 -> 经济结构”的传导力核心阻滞点。消费者生活动力差为正 8.3035,说明居民部门并未进入消费动力完全失效状态,但正向缓冲并不厚,消费意愿“更接近谨慎”修复而非强烈扩张。货币流向实体传导分为 59.9156,说明货币到实体经济的传导链条尚未断裂,但传导效率仍受到结构性阻滞和消费信心约束。
最关键的真实阻滞点从 V7 自检中的“消费 -> 生产流通”转移到 V8 真实数据中的“政治结构 -> 经济结构”。这不是小变化。它表示在 54 项真实指标里,模型认为最大阻滞不是居民消费直接不能传到生产端,而是治理、财政、债务、腐败控制、分配结构、债券发行等结构变量对经济结构形成了更强约束。换句话说,●V8 真实运行的诊断重心更偏“制度—财政—分配—市场结构”的上游阻滞,而不是单纯的需求端阻滞。
从单指标看,V8 真实数据中明显的压力源包括:中央政府债券发行、中央政府债券发行同比、赤字历史、基尼系数、基尼增长、政府腐败类变量、军费相关变量、私人信心指数、企业信心 minmax、投资增长、房地产销售增长、关税指数等。其中,债务率本身并不高,中央政府债务 GDP 比率显示低收缩压力和较高财政缓冲;但债券发行、赤字和军费类变量却显示较高压力,这说明模型区分了“债务存量低”与“财政融资压力上升”这两类不同信号。
经过量纲擦除模式的数据分析来看,中国经济在该模型下不是断裂式收缩,也不是强劲扩张,而是货币、外汇、部分总量指标仍提供支撑;但治理结构、财政融资、分配结构、信心和投资链条形成反向压力,使系统处于“可维持但不舒展”的局部阻滞状态
B. 第一类问题:财政融资压力上升,但债务存量表面仍低
V9 最清楚地区分了“债务存量低”和“新增融资压力高”。中央政府债务 GDP 比率最新值为 27.0,量纲擦除压力只有 0.069861,扩张支持为 0.927109,说明从中央政府显性债务存量看,模型认为仍有财政缓冲空间。
但中央政府债券发行指标的压力分数达到 1.0,中央政府债券发行同比压力分数为 0.954472,收缩压力分别为 65.5188 和 66.2074。这说明问题不在“债务率已经很高”,而在“财政融资增速或融资依赖度上升”。换句话说,政府仍有举债空间,但越来越需要通过债券发行维持财政和投资链条,这会带来中期财政可持续性压力。
这透露出的中国问题是:财政系统不是静态债务危机,而是动态融资压力增强。中央财政债务率低可以提供缓冲,但如果地方财政、专项债、城投、土地财政和隐性债务没有同步纳入,模型仍可能低估真实财政压力。
C. 第二类问题:消费和收入不是崩塌,但内需动力偏弱
消费增长最新值为 3.8,低于你设定的 4.5 基准线,量纲擦除压力为 0.246,支持为 0.685897,净收缩差为 -31.8922。这个结果说明消费仍有正向贡献,但强度不足,不是强劲消费扩张。
收入增长最新值为 3.9,低于 5.0 基准线,压力为 0.316667,支持为 0.639665,净收缩差为 -22.3716。它说明居民收入仍在增长,但收入增速弱于政策锚点,对消费的支撑不厚。
这透露出的中国问题是:居民部门没有完全失效,但处在谨慎消费和弱收入预期状态。消费不是系统性塌陷,而是“不够强”;收入不是负增长,而是“传导不足”。这会导致货币宽松和财政扩张难以完全转化为终端消费需求。
D. 第三类问题:投资与房地产链条仍是核心拖累
投资增长最新值为 -3.8,已经低于你设定的投资临界线 -3.0,量纲擦除压力为 0.883867,收缩压力为 60.9353。基础设施增长为 -2.2,压力为 0.784667,说明投资链条的压力不只是房地产,还涉及更广义的资本形成不足。
房地产开发投资增长为 -9.8,接近房地产深度收缩阈值;房地产销售增长为 -12.6,压力为 0.900727,收缩压力为 62.1229。这说明房地产链条尚未真正完成出清,销售端和投资端仍然同步拖累市场结构。
这透露出的中国问题是:增长底盘中最弱的不是价格,而是资产负债表和资本形成。房地产销售弱会影响房企现金流、地方土地财政、居民资产预期、银行抵押链条和建材制造;投资收缩会压低未来供给扩张和企业订单预期。
E. 第四类问题:民间信心分裂,企业信心指标存在口径冲突
V9 中 ENTREPRENEUR_CONFIDENCE_INDEX_2009_2025 最新值为 98.8,支持力接近 1,扩张压力为 83.2808,显示很强正向信心。但 ENTREPRENEUR_CONFIDENCE_MINMAX_2009_2025 最新值为 0.0034,压力为 0.927138,收缩压力为 100.0;PRIVATE_CONFIDENCE_INDEX_2009_2025 同样显示压力 0.927138,收缩压力 100.0。
这不是简单的经济结论,而是一个数据口径警报:同类“信心”变量之间存在显著冲突。一个企业信心指标显示极强支持,另一个 minmax 信心指标显示极高压力。说明 V9 虽然加入语义审计,但仍需要对“原始指数”和“minmax派生指数”做互斥处理或去重,否则会让信心链条同时出现强扩张和强收缩。
这透露出的中国问题是:信心本身可能存在分层分裂。官方或总量景气指标可能不差,但私人部门、民间资本或经过归一化处理后的信心变量显示压力偏高。经济含义上,这更接近“官方景气不等于民间风险偏好恢复”。
F. 第五类问题:价格不是主要通胀危机,但存在价格口径与通缩压力问题
CPI 同比 1.2 和 0.6 的压力较低,PPI 同比 0.5 和 -1.8 的压力也不高,说明模型没有把当前价格链条识别为高通胀压力。
但 CPI_CHINA_2009_2025 被识别为价格指数水平转同比后,阈值输入值达到 10.25641,压力为 0.940556;CPI_CONSUMER_PRICE_INDEX_DATA 转换后阈值输入值为 -2.534113,压力为 0.783811。这说明价格指数水平转同比的逻辑仍可能存在异常:一个 CPI 口径显示高通胀压力,另一个显示通缩压力。
这透露出的中国问题有两层。经济层面,价格链不是主风险,但低通胀、PPI 偏弱和需求不足仍需关注。模型层面,价格指数口径还需要继续校验,否则指数基期、同比转换和数据长度会制造伪压力。
G. 第六类问题:货币与外汇链条有托底,但传导效率不稳定
V9 中货币流向实体传导分为 49.8763,只能算中等,不是很强。M2 和 GDP、名义 GDP 的传导边被识别为压力缓释或逆周期关系,说明货币扩张对总量有托底作用,但不是强传导。
同时,M2_TRILLION 在 V9 中被转换为 M2 增长口径后,压力分数为 1.0,支持只有 0.003011,收缩压力 84.2896。这个结果和 OFFLINE_M2_YOY 的低压力、高支持形成冲突。OFFLINE_M2_YOY 显示阈值输入值 7.6,压力只有 0.016,支持 0.829818。
这透露出的问题是:货币总量指标与货币同比指标不能同时作为独立强信号使用。M2 存量转同比可能因序列构造问题产生极端值;更可靠的是直接使用 M2 同比、社融同比、贷款同比、居民中长期贷款和企业中长期贷款。经济含义上,货币仍能托底,但是否能有效流入居民消费和民企投资,还没有被模型充分证明。
H. 第七类问题:分配结构与治理变量不是崩塌压力,但仍是深层约束
基尼系数最新值 0.474,压力为 0.333333,支持为 0.658225;政府腐败代理变量压力为 0.545,支持为 0.5076;Transparency International CPI 已被正确归入治理结构而不是消费价格,压力为 0.35,支持为 0.648。
这说明 V9 不再把治理变量误放入价格链,这是进步。经济含义是:治理和分配问题没有在模型中表现为即时崩塌,但会通过信心、资源配置、财政效率和消费倾向形成慢变量压力。
这透露出的中国问题是:深层约束不一定以高频危机形式出现,而是通过分配结构、行政效率、反腐治理、民间信心和财政资金效率影响经济传导质量。
I. 综合判断
按 V9 结果,中国经济暴露出六个主要问题。
第一,财政融资压力上升,但中央显性债务率仍有缓冲。第二,消费和收入仍有正向支撑,但居民部门没有形成强扩张。第三,投资和房地产链条仍是最大实体拖累之一。第四,民间信心和企业信心存在口径分裂,说明预期修复不均衡。第五,价格链条不是主要危机,但价格指数口径仍需校正,低通胀和PPI弱势仍对应需求不足。第六,货币和外汇提供托底,但货币到实体的传导效率只是中等,不能直接解释为强复苏。
最终结论是:V9 数据透露出的中国问题不是“全面失控”,而是“托底能力尚在、结构性阻滞尚未解除”。中国经济还能维持正向循环表象,但这个循环并不舒展;最危险的不是单一总量指标下跌,而是投资、地产、民间信心、财政融资和分配结构这些慢变量互相叠加,压低长期内生增长能力。
[系统] 正在启动南柯舟矩阵因果关系分析引擎 V9 语义口径审计量纲擦除双通道压力传导模式堆垒迭代版
=======================================
* Serving Flask app 'economic_pressure_transmission_stack_engine_v9'
* Debug mode: off
本系统成功动态挂载 54 个多维宏观中国经济指标。
================ V9 语义口径审计量纲擦除双通道压力传导模式堆垒迭代交叉诊断报告 ================
[公式识别数量] 46
[公式识别状态] True
[系统涨缩阶段] 正向良性传导主导
[系统收缩压力] 28.1578
[系统扩张压力] 51.8705
[系统净收缩压力] -23.7127
[跨变量关系能量] 0.01110835
[语义口径审计指标数] 54
[数据来源分布] {'local_data': 26, 'official_data': 16, 'proxy_data': 12}
[指标口径分布] {'corruption_proxy': 3, 'debt_gdp_ratio': 1, 'deficit_ratio_or_proxy': 1, 'fiscal_claim_ratio': 1, 'fiscal_financing_level': 1, 'fiscal_financing_yoy': 1, 'fiscal_spending_level': 1, 'fx_position_level': 1, 'generic_numeric_series': 3, 'governance_index_level': 2, 'governance_wgi_estimate': 2, 'growth_or_rate': 18, 'index_level': 4, 'inequality_ratio_or_proxy': 3, 'mom_percent': 1, 'monetary_level': 1, 'nominal_level': 2, 'price_index_level': 2, 'ratio_or_share': 1, 'reserve_level': 1, 'yoy_percent': 4}
[压力传导模式] 政治结构-经济结构-市场结构-民生驱动力-消费反馈-生产流通-银行信用-财政政治闭环
[正向链指数] 49.4757
[反向链指数] 26.8483
[消费者生活动力-承受压力差] 15.5197
[货币流向实体传导分] 49.8763
[闭环状态] 正向良性循环占优
[阻滞点数量] 0
[前十传导边] GINI_CHINA_2009_2025 -> ENTREPRENEUR_CONFIDENCE_INDEX_2009_2025 tauP=0 tauS=0 prior=0.92 pressure_rel=-0.636029 support_rel=-0.620163 net_weight=-0.699256 effect=pressure_relief_or_countercyclical
GINI_COEFF_CHINA_2009_2025 -> ENTREPRENEUR_CONFIDENCE_INDEX_2009_2025 tauP=0 tauS=0 prior=0.92 pressure_rel=-0.636029 support_rel=-0.620163 net_weight=-0.699256 effect=pressure_relief_or_countercyclical CORRUPTION_INDEX_FROM_CPI_2009_2025 -> ENTREPRENEUR_CONFIDENCE_INDEX_2009_2025 tauP=0 tauS=0 prior=0.92 pressure_rel=-0.599188 support_rel=-0.622029 net_weight=-0.665706 effect=pressure_relief_or_countercyclical
TI_CPI_DERIVED_CORRUPTION_2009_2025 -> ENTREPRENEUR_CONFIDENCE_INDEX_2009_2025 tauP=0 tauS=0 prior=0.92 pressure_rel=-0.599188 support_rel=-0.622029 net_weight=-0.665706 effect=pressure_relief_or_countercyclical CPI_CHINA_2009_2025 -> NOMINAL_GDP_DATA tauP=0 tauS=0 prior=0.82 pressure_rel=-0.671229 support_rel=-0.62266 net_weight=-0.652524 effect=pressure_relief_or_countercyclical
GOVERNMENT_CORRUPTION_WGI_2009_2025 -> ENTREPRENEUR_CONFIDENCE_INDEX_2009_2025 tauP=0 tauS=0 prior=0.92 pressure_rel=-0.557773 support_rel=-0.604707 net_weight=-0.624417 effect=pressure_relief_or_countercyclical
M2_TRILLION -> GDP_100M tauP=0 tauS=0 prior=0.76 pressure_rel=-0.673313 support_rel=-0.673253 net_weight=-0.614052 effect=pressure_relief_or_countercyclical
M2_TRILLION -> NOMINAL_GDP_DATA tauP=1 tauS=1 prior=0.76 pressure_rel=-0.673313 support_rel=-0.673253 net_weight=-0.614052 effect=pressure_relief_or_countercyclical
FX_POSITION_TOTAL -> NOMINAL_GDP_DATA tauP=0 tauS=0 prior=0.76 pressure_rel=-0.672564 support_rel=-0.668486 net_weight=-0.612758 effect=pressure_relief_or_countercyclical
EXCHANGE_RATES -> SECTOR_SHARE_REAL_ESTATE tauP=1 tauS=1 prior=0.88 pressure_rel=0.672443 support_rel=0.664145 net_weight=0.270304 effect=positive_support
[单指标压力]
指标:CENTRAL_GOVERNMENT_BOND_ISSUANCE_2009_2025
├─ 数据处理: [已进行量纲擦除]
├─ 类别: fiscal_debt ├─ 语义口径: fiscal_financing_level / level_to_yoy_pct / official_data
├─ 阈值键: FISCAL_FINANCING_GROWTH
├─ 原始最新值/阈值输入值: 13.85 / 100.0
├─ 压力密度: 4.5371 (低)
├─ 量纲擦除压力0-1: 1.0
├─ 量纲擦除支持0-1: 0.18
├─ 收缩压力: 65.5188
├─ 扩张压力: 41.6887
├─ 净收缩差: 23.8301 └─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:CENTRAL_GOVERNMENT_BOND_ISSUANCE_YOY_2009_2025
├─ 数据处理: [已进行量纲擦除]
├─ 类别: fiscal_debt
├─ 语义口径: fiscal_financing_yoy / level / official_data
├─ 阈值键: FISCAL_FINANCING_GROWTH ├─ 原始最新值/阈值输入值: 70.54 / 70.54
├─ 压力密度: 3.9619 (低)
├─ 量纲擦除压力0-1: 0.954472
├─ 量纲擦除支持0-1: 0.112783
├─ 收缩压力: 66.2074
├─ 扩张压力: 36.8726
├─ 净收缩差: 29.3348
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:CENTRAL_GOVERNMENT_DEBT_GDP_RATIO_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 类别: fiscal_debt
├─ 语义口径: debt_gdp_ratio / level / official_data
├─ 阈值键: DEBT_GDP_RATIO
├─ 原始最新值/阈值输入值: 27.0 / 27.0
├─ 压力密度: 3.2585 (低)
├─ 量纲擦除压力0-1: 0.069861 ├─ 量纲擦除支持0-1: 0.927109
├─ 收缩压力: 8.938
├─ 扩张压力: 72.0
├─ 净收缩差: -63.062
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:CHINA_CPI_MONTHLY_YOY_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 类别: consumer_price ├─ 语义口径: yoy_percent / level / official_data
├─ 阈值键: CPI_YOY
├─ 原始最新值/阈值输入值: 1.2 / 1.2
├─ 压力密度: 1.7105 (低)
├─ 量纲擦除压力0-1: 0.064
├─ 量纲擦除支持0-1: 0.755613
├─ 收缩压力: 10.1007
├─ 扩张压力: 71.0479
├─ 净收缩差: -60.9473 └─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:CHINA_CPI_YOY_PCT
├─ 数据处理: [原始增长率体系]
├─ 类别: consumer_price
├─ 语义口径: yoy_percent / level / official_data
├─ 阈值键: CPI_YOY
├─ 原始最新值/阈值输入值: 0.6 / 0.6 ├─ 压力密度: 18.2103 (低)
├─ 量纲擦除压力0-1: 0.112
├─ 量纲擦除支持0-1: 0.696358
├─ 收缩压力: 13.3616
├─ 扩张压力: 66.1332
├─ 净收缩差: -52.7717
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:CHINA_PPI_MONTHLY_MOM ├─ 数据处理: [原始增长率体系]
├─ 类别: producer_price
├─ 语义口径: mom_percent / level / official_data
├─ 阈值键: PPI_MOM
├─ 原始最新值/阈值输入值: 0.2 / 0.2
├─ 压力密度: 24.5288 (低)
├─ 量纲擦除压力0-1: 0.048
├─ 量纲擦除支持0-1: 0.813607
├─ 收缩压力: 7.796 ├─ 扩张压力: 76.3235
├─ 净收缩差: -68.5274
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:CHINA_PPI_MONTHLY_YOY_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 类别: producer_price
├─ 语义口径: yoy_percent / level / official_data ├─ 阈值键: PPI_YOY
├─ 原始最新值/阈值输入值: 0.5 / 0.5
├─ 压力密度: 1.0264 (低)
├─ 量纲擦除压力0-1: 0.02
├─ 量纲擦除支持0-1: 0.756272
├─ 收缩压力: 8.3012
├─ 扩张压力: 68.7505
├─ 净收缩差: -60.4493
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:CHINA_PPI_YOY_PCT
├─ 数据处理: [原始增长率体系]
├─ 类别: producer_price
├─ 语义口径: yoy_percent / level / official_data
├─ 阈值键: PPI_YOY
├─ 原始最新值/阈值输入值: -1.8 / -1.8
├─ 压力密度: 23.6934 (低)
├─ 量纲擦除压力0-1: 0.072 ├─ 量纲擦除支持0-1: 0.758725
├─ 收缩压力: 12.4834
├─ 扩张压力: 69.4272
├─ 净收缩差: -56.9438
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:CONSUMPTION_GROWTH
├─ 数据处理: [原始增长率体系]
├─ 类别: domestic_demand ├─ 语义口径: growth_or_rate / level / local_data
├─ 阈值键: CONSUMPTION_GROWTH
├─ 原始最新值/阈值输入值: 3.8 / 3.8
├─ 压力密度: 20.6634 (低)
├─ 量纲擦除压力0-1: 0.246
├─ 量纲擦除支持0-1: 0.685897
├─ 收缩压力: 32.3069
├─ 扩张压力: 64.1991
├─ 净收缩差: -31.8922 └─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:CONTROL_OF_CORRUPTION_WGI_ESTIMATE_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 类别: structure_governance
├─ 语义口径: governance_wgi_estimate / level / proxy_data
├─ 阈值键: GOVERNANCE_WGI_ESTIMATE ├─ 原始最新值/阈值输入值: 0.0 / 0.0
├─ 压力密度: -0.0891 (低)
├─ 量纲擦除压力0-1: 0.12
├─ 量纲擦除支持0-1: 0.912801
├─ 收缩压力: 20.5582
├─ 扩张压力: 77.8778
├─ 净收缩差: -57.3195
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:CORRUPTION_INDEX_FROM_CPI_2009_2025
├─ 数据处理: [已进行量纲擦除]
├─ 类别: structure_governance
├─ 语义口径: corruption_proxy / level / proxy_data
├─ 阈值键: CORRUPTION_PROXY_0_100
├─ 原始最新值/阈值输入值: 57.0 / 57.0
├─ 压力密度: 14.5939 (低)
├─ 量纲擦除压力0-1: 0.246
├─ 量纲擦除支持0-1: 0.72288 ├─ 收缩压力: 23.5836
├─ 扩张压力: 72.3059
├─ 净收缩差: -48.7223
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:CPI_CHINA_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 类别: consumer_price
├─ 语义口径: price_index_level / level_to_yoy_pct / official_data
├─ 阈值键: CPI_YOY
├─ 原始最新值/阈值输入值: 43.0 / 10.25641
├─ 压力密度: 0.8717 (低)
├─ 量纲擦除压力0-1: 0.940556
├─ 量纲擦除支持0-1: 0.167105
├─ 收缩压力: 67.6001
├─ 扩张压力: 27.802
├─ 净收缩差: 39.7982
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:CPI_CHINA_TI_OFFICIAL_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 类别: structure_governance
├─ 语义口径: governance_index_level / level / proxy_data
├─ 阈值键: GOVERNANCE_SCORE_0_100
├─ 原始最新值/阈值输入值: 43.0 / 43.0
├─ 压力密度: 6.2343 (低) ├─ 量纲擦除压力0-1: 0.35
├─ 量纲擦除支持0-1: 0.648
├─ 收缩压力: 43.2401
├─ 扩张压力: 56.3789
├─ 净收缩差: -13.1388
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:CPI_CONSUMER_PRICE_INDEX_DATA
├─ 数据处理: [原始增长率体系] ├─ 类别: consumer_price
├─ 语义口径: price_index_level / level_to_yoy_pct / official_data
├─ 阈值键: CPI_YOY
├─ 原始最新值/阈值输入值: 100.0 / -2.534113
├─ 压力密度: 27.0253 (低)
├─ 量纲擦除压力0-1: 0.783811
├─ 量纲擦除支持0-1: 0.165383
├─ 收缩压力: 57.2776
├─ 扩张压力: 29.7403 ├─ 净收缩差: 27.5373
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:DEFICIT_HISTORY_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 类别: fiscal_debt
├─ 语义口径: deficit_ratio_or_proxy / abs_level / official_data
├─ 阈值键: DEFICIT_RATIO ├─ 原始最新值/阈值输入值: 4.0 / 4.0
├─ 压力密度: 0.4375 (低)
├─ 量纲擦除压力0-1: 0.3
├─ 量纲擦除支持0-1: 0.610285
├─ 收缩压力: 22.2776
├─ 扩张压力: 68.2851
├─ 净收缩差: -46.0075
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:ENTREPRENEUR_CONFIDENCE_INDEX_2009_2025
├─ 数据处理: [已进行量纲擦除]
├─ 类别: confidence
├─ 语义口径: index_level / level / local_data
├─ 阈值键: CONFIDENCE_INDEX
├─ 原始最新值/阈值输入值: 98.8 / 98.8
├─ 压力密度: 13.344 (低)
├─ 量纲擦除压力0-1: 0.046092
├─ 量纲擦除支持0-1: 0.998769
├─ 收缩压力: 19.3437 ├─ 扩张压力: 83.2808
├─ 净收缩差: -63.9371
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:ENTREPRENEUR_CONFIDENCE_MINMAX_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 类别: confidence
├─ 语义口径: index_level / level / local_data
├─ 阈值键: CONFIDENCE_INDEX ├─ 原始最新值/阈值输入值: 0.0034 / 0.0034
├─ 压力密度: 79.9528 (高)
├─ 量纲擦除压力0-1: 0.927138
├─ 量纲擦除支持0-1: 0.219442
├─ 收缩压力: 100.0
├─ 扩张压力: 21.4327
├─ 净收缩差: 78.5673
└─ 理论诊断建议: 结构性压力聚集,注意财政与流 动性传导。
指标:EXCHANGE_RATES
├─ 数据处理: [原始增长率体系]
├─ 类别: liquidity_credit
├─ 语义口径: growth_or_rate / level / local_data
├─ 阈值键: None
├─ 原始最新值/阈值输入值: 7.08 / 7.08
├─ 压力密度: 1.104 (低)
├─ 量纲擦除压力0-1: 0.053226
├─ 量纲擦除支持0-1: 0.944498 ├─ 收缩压力: 11.3387
├─ 扩张压力: 83.6906
├─ 净收缩差: -72.3519
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:FX_POSITION_TOTAL
├─ 数据处理: [已进行量纲擦除]
├─ 类别: liquidity_credit
├─ 语义口径: fx_position_level / level_to_yoy_pct / official_data
├─ 阈值键: FX_RESERVE_GROWTH
├─ 原始最新值/阈值输入值: 3.33 / 25.18797
├─ 压力密度: 2.5517 (低)
├─ 量纲擦除压力0-1: 0.952777
├─ 量纲擦除支持0-1: 0.13997
├─ 收缩压力: 61.3546
├─ 扩张压力: 36.3626
├─ 净收缩差: 24.992
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:FX_RESERVES_USD_BN
├─ 数据处理: [原始增长率体系]
├─ 类别: liquidity_credit
├─ 语义口径: reserve_level / level_to_yoy_pct / official_data
├─ 阈值键: FX_RESERVE_GROWTH
├─ 原始最新值/阈值输入值: 3357.9 / -12.177324
├─ 压力密度: 0.3041 (低) ├─ 量纲擦除压力0-1: 0.720801
├─ 量纲擦除支持0-1: 0.094352
├─ 收缩压力: 43.7519
├─ 扩张压力: 37.9728
├─ 净收缩差: 5.7792
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:FX_RESERVE_GROWTH
├─ 数据处理: [原始增长率体系] ├─ 类别: liquidity_credit
├─ 语义口径: growth_or_rate / level / local_data
├─ 阈值键: FX_RESERVE_GROWTH
├─ 原始最新值/阈值输入值: 4.2 / 4.2
├─ 压力密度: 43.9199 (中)
├─ 量纲擦除压力0-1: 0.139
├─ 量纲擦除支持0-1: 0.487788
├─ 收缩压力: 17.0347
├─ 扩张压力: 55.754 ├─ 净收缩差: -38.7193
└─ 理论诊断建议: 密切监测经济被动扩张与资产负 债表结构。
指标:FX_RESERVE_GROWTH_CHINA_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 类别: liquidity_credit
├─ 语义口径: growth_or_rate / level / local_data
├─ 阈值键: FX_RESERVE_GROWTH ├─ 原始最新值/阈值输入值: 4.2 / 4.2
├─ 压力密度: 43.9199 (中)
├─ 量纲擦除压力0-1: 0.139
├─ 量纲擦除支持0-1: 0.487788
├─ 收缩压力: 17.0347
├─ 扩张压力: 55.754
├─ 净收缩差: -38.7193
└─ 理论诊断建议: 密切监测经济被动扩张与资产负 债表结构。
指标:GDP_100M
├─ 数据处理: [已进行量纲擦除]
├─ 类别: domestic_demand
├─ 语义口径: nominal_level / level_to_yoy_pct / official_data
├─ 阈值键: GDP_GROWTH
├─ 原始最新值/阈值输入值: 1540000.0 / 100.0
├─ 压力密度: 5.4524 (低)
├─ 量纲擦除压力0-1: 0.0
├─ 量纲擦除支持0-1: 1.0 ├─ 收缩压力: 25.0736
├─ 扩张压力: 73.905
├─ 净收缩差: -48.8314
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:GINI_CHINA_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 类别: structure_governance
├─ 语义口径: inequality_ratio_or_proxy / gini_ratio / proxy_data
├─ 阈值键: GINI_RATIO
├─ 原始最新值/阈值输入值: 0.474 / 0.474
├─ 压力密度: 0.0734 (低)
├─ 量纲擦除压力0-1: 0.333333
├─ 量纲擦除支持0-1: 0.658225
├─ 收缩压力: 28.0128
├─ 扩张压力: 68.3464
├─ 净收缩差: -40.3336
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:GINI_COEFF_CHINA_2009_2025 ├─ 数据处理: [原始增长率体系]
├─ 类别: structure_governance
├─ 语义口径: inequality_ratio_or_proxy / gini_ratio / proxy_data ├─ 阈值键: GINI_RATIO ├─ 原始最新值/阈值输入值: 0.474 / 0.474 ├─ 压力密度: 0.0734 (低)
├─ 量纲擦除压力0-1: 0.333333
├─ 量纲擦除支持0-1: 0.658225 ├─ 收缩压力: 28.0128
├─ 扩张压力: 68.3464
├─ 净收缩差: -40.3336
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:GINI_GROWTH_CHINA_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 类别: structure_governance
├─ 语义口径: inequality_ratio_or_proxy / gini_ratio / proxy_data
├─ 阈值键: GINI_RATIO
├─ 原始最新值/阈值输入值: 0.63 / 0.0063
├─ 压力密度: 60.009 (中)
├─ 量纲擦除压力0-1: 0.088366
├─ 量纲擦除支持0-1: 0.828872
├─ 收缩压力: 12.9656
├─ 扩张压力: 80.9389 ├─ 净收缩差: -67.9733 └─ 理论诊断建议: 密切监测经济被动扩张与资产负 债表结构。
指标:GOVERNMENT_CLEANLINESS_WGI_2009_2025 ├─ 数据处理: [原始增长率体系]
├─ 类别: structure_governance ├─ 语义口径: governance_wgi_estimate / level / proxy_data
├─ 阈值键: GOVERNANCE_WGI_ESTIMATE ├─ 原始最新值/阈值输入值: 0.0 / 0.0 ├─ 压力密度: 4.6031 (低)
├─ 量纲擦除压力0-1: 0.12 ├─ 量纲擦除支持0-1: 0.714461 ├─ 收缩压力: 10.5019
├─ 扩张压力: 75.6763 ├─ 净收缩差: -65.1744 └─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。 指标:GOVERNMENT_CORRUPTION_WGI_2009_2025
├─ 数据处理: [已进行量纲擦除] ├─ 类别: structure_governance ├─ 语义口径: corruption_proxy / level / proxy_data ├─ 阈值键: CORRUPTION_PROXY_0_100 ├─ 原始最新值/阈值输入值: 69.8 / 69.8
├─ 压力密度: 14.7596 (低) ├─ 量纲擦除压力0-1: 0.545 ├─ 量纲擦除支持0-1: 0.5076
├─ 收缩压力: 45.7188 ├─ 扩张压力: 56.0578
├─ 净收缩差: -10.3391
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:H_LIST
├─ 数据处理: [原始增长率体系]
├─ 类别: unknown
├─ 语义口径: generic_numeric_series / level / local_data
├─ 阈值键: None ├─ 原始最新值/阈值输入值: 33.0 / 33.0
├─ 压力密度: 5.2974 (低)
├─ 量纲擦除压力0-1: 0.05868
├─ 量纲擦除支持0-1: 0.937958
├─ 收缩压力: 13.0238
├─ 扩张压力: 83.817
├─ 净收缩差: -70.7932
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:INCOME_GROWTH_CHINA_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 类别: domestic_demand
├─ 语义口径: growth_or_rate / level / local_data
├─ 阈值键: INCOME_GROWTH
├─ 原始最新值/阈值输入值: 3.9 / 3.9
├─ 压力密度: 29.3627 (低)
├─ 量纲擦除压力0-1: 0.316667
├─ 量纲擦除支持0-1: 0.639665 ├─ 收缩压力: 37.6663
├─ 扩张压力: 60.0379
├─ 净收缩差: -22.3716
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:INFRASTRUCTURE_GROWTH
├─ 数据处理: [原始增长率体系]
├─ 类别: domestic_demand
├─ 语义口径: growth_or_rate / level / local_data
├─ 阈值键: INVESTMENT_GROWTH
├─ 原始最新值/阈值输入值: -2.2 / -2.2
├─ 压力密度: 17.5563 (低)
├─ 量纲擦除压力0-1: 0.784667
├─ 量纲擦除支持0-1: 0.244538
├─ 收缩压力: 56.2591
├─ 扩张压力: 43.8204
├─ 净收缩差: 12.4387
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:INVESTMENT_GROWTH
├─ 数据处理: [原始增长率体系]
├─ 类别: domestic_demand
├─ 语义口径: growth_or_rate / level / local_data
├─ 阈值键: INVESTMENT_GROWTH
├─ 原始最新值/阈值输入值: -3.8 / -3.8
├─ 压力密度: 11.6012 (低) ├─ 量纲擦除压力0-1: 0.883867
├─ 量纲擦除支持0-1: 0.174232
├─ 收缩压力: 60.9353
├─ 扩张压力: 41.0194
├─ 净收缩差: 19.916
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
指标:L_LIST
├─ 数据处理: [已进行量纲擦除] ├─ 类别: unknown
├─ 语义口径: generic_numeric_series / level / local_data
├─ 阈值键: None
├─ 原始最新值/阈值输入值: 305.0 / 305.0
├─ 压力密度: 12.9755 (低)
├─ 量纲擦除压力0-1: 0.032716
├─ 量纲擦除支持0-1: 0.971367
├─ 收缩压力: 13.604
├─ 扩张压力: 85.9207 ├─ 净收缩差: -72.3166
└─ 理论诊断建议: 压力出清或安全边界充裕,可适 度扩张。
俄罗斯研究
俄罗斯财政研究
俄罗斯国家的深层财务财政危机
董斌
基于南柯舟研发的 SIS4 军事/政治/经济国家状态空间模型(因果约束的现实锚定解释)的 JSON 运行结果,对俄罗斯(涵盖2009-2025年数据及2026年前瞻预测)的国家运行状态进行了深度诊断与分析。
模型基础:基于南柯舟自行研发的 SIS4 军事/政治/经济国家状态空间模型(State Space Model with causal constraints and reality anchoring)。这是一个试图用数学/系统动力学方法,将宏观经济数据、社会压力、军事支出等变量整合成“国家状态向量”进行诊断和预测的框架。
时间范围:重点分析2009–2025年历史数据 + 2026年前瞻预测。
风格:结合官方数据(俄央行、财政部等)、智库报告(PIIE、高盛、Meduza等)和模型推导,带有较强的预警/诊断色彩,强调“结构性危机”和“隐性压力积累”。
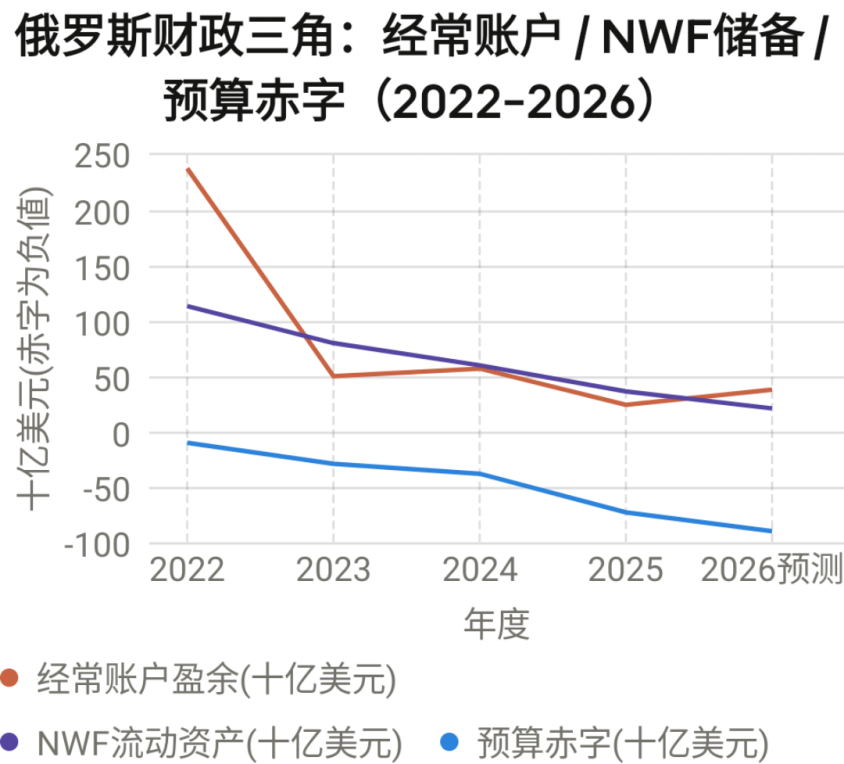
●2025年度的现状
2025年1–5月俄罗斯经常账户:权威数据逐月解剖
俄央行数据显示,2025年1–5月经常账户盈余为243亿美元,同比大幅收窄34.7%(2024年同期为372亿美元)。贸易顺差479亿美元,同比下降19%。
●国际社会的高估和今日现状
布鲁金斯以及其它智库估计,俄罗斯经常账户盈余~520亿美元的估算高估约25–40%,当前趋势指向360–420亿美元,且存在进一步下修风险。
最新数据显示,2026年,俄罗斯经常账户盈余有枯竭风险,最新数据已显示悬崖效应:
俄央行2026年1–2月数据显示,经常账户盈余仅19亿美元,相比2025年同期的104亿美元下降82%。
2026年2月单月盈余仅16亿美元,而2025年2月为76亿美元。贸易顺差从2025年2月的111亿美元萎缩至54亿美元。 (Meduza)
2026年1月,联邦油气收入同比暴跌50.2%至393亿卢布,为新冠疫情以来最低。1–2月联邦赤字达3.449万亿卢布(约GDP的1.5%),较上年同期扩大27.7%。
●油气收入
油价实际走势 vs 假设:
俄罗斯5月卢布计价油价已从2024年5月的每桶6122卢布暴跌至4190卢布,1–6月油气收入同比下降17%,6月油气收入降至2023年1月以来最低。 (PIIE)
以下是基于实际数据的全年盈余区间重新估算:
1–5月已实现: 243亿美元区间
6月估算: ~70亿美元(同比-42%趋势延续)
Q3季节性: 150–180亿美元(服务赤字扩大拖累)
Q4季节性: 100–130亿美元
━━━━━━━━━━━━━━━━━━━━━━━
全年合理区间: 360–420亿美元
520亿美元: 需要H2平均月度盈余60亿+,
但5月仅30亿,且趋势向下。
●油气收入——财政地基的结构性侵蚀
俄罗斯财政部数据显示:俄罗斯从2025年油气收入仅8.3万亿卢布(1079亿美元),远低于原预算假设的10.9万亿卢布(1417亿美元),缺口达338亿美元。NWF流动资产已降至2019年以来最低水平,从2022年初的峰值1135亿美元缩水超三分之二。 (数据来源:Stiftung Wissenschaft und Politik)
俄罗斯政府乌拉尔原油价格假设早已从2024年9月估值下修至2025年均价56美元/桶,高盛也早已警告2026年油价可能跌至40美元,当然已经对俄罗斯财政造成进一步冲击。 (数据来源:Eurasia Review)
财政触发阈值体系正在系统性失效:
俄罗斯政府面临三难困境:一是动用NWF覆盖赤字(但加速耗尽安全垫);二是将财政规则触发油价下调至50美元(实质上是预算强制削减);三是货币贬值(提高卢布计价油气收入但引发通胀)。三条路径均有重大代价。 (The Moscow Times)
●结构性收缩
关键结构性问题: 盈余不是来自出口扩张,而是进口收缩(意味着深刻的需求收缩/资金缺口等多方原因)。出口总额1628亿美元同比仅降5.7%,但服务赤字扩大26.4%至158亿美元,进口增长1.3%至1150亿美元。 (World Socialist Web Site) 这意味着盈余质量在劣化——是"被迫节省"而非"创汇能力增强"。
●收入结构分析:
2023–2024年俄罗斯经常账户盈余已从2022年的2300亿美元骤降至500–600亿美元,2025年预计约520亿美元——这一数字基于油价约70–75美元/桶的基准假设。 (RFE/RL)
但现实数据已证明这一假设过于乐观:
油价实际走势 vs 假设:
俄罗斯5月卢布计价油价已从2024年5月的每桶6122卢布暴跌至4190卢布,1–6月油气收入同比下降17%,6月油气收入降至2023年1月以来最低。 (PIIE)
■基于基于南柯舟研发的 SIS4 军事政治国家状态空间模型,这份报告的核心在于捕捉传统宏观经济数据背后的结构性与底层社会压力弱信号。以下是针对俄罗斯数据的核心分析结论:
1. 核心结论与总体评估 (Executive Summary)
社会整体状态 :当前(2025年)俄罗斯的社会压力指数(Social Stress Index)为 14.81,系统暂时判定整体状态为表面“稳定 (stable)。
现实锚定解释力:模型对俄罗斯的风险压力解释力分数高达 75.44 分 (High),表明模型推导出的风险传导链条与当前现实观测数据的吻合度极高(尤其是物理阈值锚定率达到100%)。
首要系统性风险:最大的潜在脆弱性完全集中在“军费挤出压力链” (Military expenditure crowding-out pressure chain)。
2. 2025年核心宏观特征与阈值触发
尽管俄罗斯账面上的宏观经济数据部分表现尚可,但底层结构已经严重倾斜:
军费激增(核心触发点):军费占 GDP 的比重攀升至惊人的 7.50%。这直接触发了 military_over_growth_flag (军费挤出观察区) 的红色警报。
经济表面温和但通胀承压:2025年 GDP 增长率为 4.34%,失业率极低(仅为 2.13%)。但是,CPI 达到了 8.43%,表明国内面临较高的通胀压力。
财政与债务仍在安全区:政府财政盈余/赤字占比为 +1.31%,政府债务占 GDP 比例仅为 17.95%,外汇储备能够覆盖 16.7 个月的进口,外债占比 16.75%。这说明俄罗斯目前在外围主权信用和政府债务上并未出现危机。
系统性密度过载:虽然单一指标(除军费外)未全线崩溃,但系统叠加计算出的 pressure_density (堆垒迭代密度) 达到了0.148,远超 0.079 的危险临界点,说明各种隐性压力(低效增长、通胀、军费)正在内部产生系统性的过载。
3. 深度剖析:军费挤出压力链 (最高级别风险)
模型将“军费挤出压力链”标记为优先级最高、严重程度级别为 High (0.792)的监控项。
传导逻辑:由于军费占 GDP 的比例过高,甚至超过了经济增长的动能。这种结构必然导致财政支出的强制重分配。
现实后果 :系统指出,这会通过 “公共投资被压缩” 和 “民生支出被挤出” 以及 “资本形成下降” 传导至更广泛的社会压力。
验证与反证机制 :模型提示需严密监控以下指标。如果未来看到“军费占GDP下降”或“民生支出依然稳定增加”,则该风险判断可以下调;反之,如果看到“国防预算继续高速增长”、“公共投资进一步停滞”,则该风险链条完全成立。
4. 2026年弱信号前瞻预测 (Forecast)
趋势反转预警 :模型对 2026 年给出了明确的 趋势反转警告 (trend_reversal_warning: true) 。
压力持续上行 :虽然预测 2026 年的名义指标变化不大(预测 GDP 4.40%,CPI 7.85%),但 SIS 系统的下期状态范数 (sis_next_state_norm) 预计将从 1.97 显著上升至 2.44 ,SIS 前瞻预测方向为 "up" 。这说明模型侦测到 社会与经济系统的内生压力在 2026 年将继续向上累积 。
5. 因果探针分析 (Causal Probes)
模型在 causal_path_probe_panel 中测试了多个变量对下一期社会压力的滞后影响:
放大压力项 (Amplifying) : 贸易依存度 (trade_pct_gdp) 和 人道主义压力 (humanitarian_pressure) 在模型中显示出放大社会压力的正向信号。
缓冲/抑制项 (Dampening) :高额的 外汇储备 (reserves_months_imports) 是目前俄罗斯缓解外部系统性冲击最强大的减震器(相关性 -0.67,抑制效应强)。
总结
根据这份数据,俄罗斯当前的经济处于一种“高耗能维稳”的状态。极低的失业率和尚可的经济增长很大程度上是由战时体制或庞大的军工复合体支出(军费占GDP 7.5%) 支撑的。这种模式的代价是内部的“军费挤出效应”极其严重。虽然外汇储备丰厚和政府债务极低保证了其短期内不会发生主权债务崩盘,但模型发出的2026年“趋势反转警告”表明,内部挤出效应带来的民生和公共资本短缺压力正在逼近临界点。
2026年的防御性消耗:当前俄罗斯的经济收入彻底转为“消耗型”财政。2025/2026年的经常账户盈余(如讨论中验证的400-500亿美元区间),正在艰难的抵御资本外逃与军费开销。2006年用于基建和福利的预算盈余,在今天已翻转为占GDP 1.7%-3%(风险情景下达5-10%)的预算赤字。
核心结论: 俄罗斯2025年经常账户盈余的绝对数字尚能维持(约360–420亿美元),但其战略意义已根本改变——盈余已不足以覆盖财政赤字,NWF缓冲垫进入最后消耗阶段,2026年盈余可能跌破200亿美元甚至更低。俄罗斯正从"制裁下的财政韧性"快速滑向"战时财政应急状态",经常账户盈余这一护城河在2026–2027年窗口内存在实质性消失的风险。

■董斌■ 致力于高维与超高维模型建构/社会动力数学模型建构与逻辑合规性审核/政治与经济大模型分析运行理论与建模设计
公共数据高数与逻辑分析
经济堆垒迭代传递系统
经济动态多维堆垒迭代交叉诊断报告
理论原创和原创系统发明人:董斌
<版本升级只是分析增维>
本文禁止任何摘抄复制转发及商业使用
董斌序言
2026 年,中国名义 GDP 基准预测值合理区间为 146.8—149.0 万亿元人民币, 将在147±2左右徘徊。这是经由堆垒迭代公式预测得到的结果。这份由V6版本的中国经济动态多维堆垒迭代交叉诊断报告,完成了在堆垒迭代理论体系建构下通过在高维数据中系统性的对弱信号进行检测寻踪,从真实(可能是噪声大、维度高、相关性强)的多指标数据中,挖掘出那些微弱但系统性(非随机)的异常信号,用于早期监察或预警。任何系统性的“弱信号”都不可能孤立的随机波动,而是多个指标协同表现出的系统性异常,值得业务人员重点关注(例如宏观风险早期预警、金融市场异动、设备健康监测等)。因此它非常具有分析价值。从堆垒迭代因果关系论的视角来看,数据揭示了一个“宏观表象稳定,但微观传导存在严重结构性阻滞” 的深层经济形态。
一个国家的政治结构制造了经济结构,如果其经济结构是合理的,那么,政府就会提高福利水平,降低消费者的压力,从而提高消费者的消费力,实际上这是一个社会结构,向消费者传递力量的过程,它展示了政治结构向社会结构(包括商业结构)传递力量的过程,如果社会结构向消费者传递了非常大的经济压力,那么消费者就会遭遇巨大的经济压力,如果消费者承受的经济压力大于经济动力,那么消费者就会降低消费力,如果国家降低腐败程度,那么经济的调控工具就会有效地发挥作用,那么政府的行政效率压力就会有效地传导到市场,于是社会福利可以有效向消费者有效的传导,那么社会福利就向消费者传递了相当大的生活动力,当消费者的生活动力大于消费者所承受的压力,那么货币发行后如果能顺利流向消费者,那么消费者就把货币消费力传导向市场,市场 再把消费力传导向销售、流通、 生产制造商,销售流通、生产制造商 再把货币需求传导向银行,银行通过发行货币向销售流通、生产制造商获取利润,政府发行货币向市场释放流动性,这样市场就开始良性循环。如果这个过程是顺利的那么一个社会就会良性循环发展。如果任何一个环节遭到了阻滞,那么整个社会循环结构就遭到了阻滞。实际上社会结构(包括经济结构)是政治结构造就的,推动社会福利结构的,其实是优化市场结构的要求,这对于优化政治结构来说是有利的,一旦市场结构变坏,经济结构的良性循环就被打破,整个的市场和政府就变得无利可图,那么政府的能力就遭受到了质疑。
经济学的正向传导模式(良性循环):政治结构 → 经济结构 → 市场结构 → 民生驱动力结构 → 消费力回馈 → 强化政治结构一个国家的政治结构(制度框架、治理模式、政策制定机制、腐败控制水平)是源头,它直接塑造经济结构(所有制结构、分配制度、财政货币政策框架、监管体系)。
若政治结构合理且高效(低腐败、高行政效率),则会形成合理的经济结构,具体表现为:政治结构优化经济结构:政府通过有效调控工具(财政、货币、产业政策)降低制度性交易成本,抑制垄断与寻租,推动市场结构向竞争性、包容性演化。经济结构改善市场结构:合理的经济结构降低企业税费负担、融资成本和准入门槛,市场结构趋向充分竞争、资源高效配置,供应链(销售-流通-生产制造)畅通。市场结构提升民生驱动力:高效市场将利润与效率转化为更高的工资、就业机会和社会福利。政府降低消费者(家庭部门)压力(住房、医疗、教育、税收负担),社会福利有效向消费者传导,消费者生活动力(收入预期+消费信心)显著增强。民生驱动力转化为消费力:当生活动力 > 承受压力时,消费者边际消费倾向上升。货币发行后能顺利流向实体(居民部门),消费力强劲。消费力回馈市场与生产:消费需求传导向销售、流通、生产制造环节,形成有效订单。制造商产生货币需求(信贷、投资),传导向银行体系。银行通过存贷利差和信用创造获取利润,同时政府通过税收与流动性管理实现财政可持续。闭环强化政治结构:市场良性循环产生充足税基、政府信誉提升、民众支持度提高,反过来巩固政治结构的合法性与执行力,形成正反馈。
完整正向链条于是形成这样的政治结构(低腐败、高效) → 合理经济结构 → 竞争性市场结构 → 强民生驱动力(福利传递) → 高消费力 → 市场订单与利润 → 银行信用扩张 → 流动性良性循环 → 经济增长 + 财政丰裕 → 政治结构进一步优化。此循环中,每个环节顺畅即形成社会经济结构的自我强化机制。
反向传导模式(恶性循环):阻滞与压力累积若政治结构出现问题(如腐败高企、治理低效、政策随意性强),传导立即反转,压力层层放大:政治结构劣化经济结构:高腐败导致调控工具失灵(货币政策传导梗阻、财政资金漏损),经济结构扭曲(垄断加剧、分配失衡、产权保护弱)。经济结构恶化市场结构:高税费、高融资成本、行政壁垒使市场结构劣化(寡头垄断、僵尸企业、供应链断裂、效率低下)。市场结构挤压民生驱动力:企业利润下降 → 就业不稳、工资增长停滞,政府福利能力减弱。消费者承受的经济压力(生活成本上升+收入不确定性)大幅增加,生活动力被严重削弱。消费力崩塌:当承受压力 > 生活动力时,消费者去杠杆、减少消费、增加储蓄(预防性储蓄)。货币发行难以流向实体(滞留金融体系或资产泡沫),形成“流动性陷阱”。需求不足反噬生产与金融:销售流通环节萎缩 → 生产制造商库存积压、利润下滑 → 信贷违约风险上升,银行惜贷或坏账增加。政府税收减少,财政压力剧增。循环反馈质疑政治结构:经济增长停滞、失业上升、社会不满加剧,政府能力遭受质疑。为维持稳定可能采取短期刺激(过度发债、货币超发),进一步扭曲经济结构,加剧市场恶化,形成负反馈。
于是形成完整反向链条政治结构(高腐败、低效) → 扭曲经济结构 → 劣化市场结构 → 弱民生驱动力(压力传导) → 低消费力 → 需求不足 → 企业-银行-财政困境 → 政治合法性下降 → 更强的控制或更严重的扭曲。反向链条形成关键阻滞点与结构性洞察核心阻滞环节:① 政治到经济的调控工具失灵(腐败);② 经济到市场的福利/红利传导断裂;③ 市场到民生的压力过度累积;④ 货币到消费的实体传导梗阻。
社会经济的结构本质:它是政治结构的“产物”与“镜像”。优化市场结构、强化民生驱动力,实质是对政治结构优化的倒逼机制——良性市场产生正外部性(税基、稳定、支持),恶性市场则产生负外部性(财政危机、社会不稳)。动态平衡条件:消费者“生活动力 > 承受压力”是整个循环能否良性运转的关键阈值。货币政策只有在这一条件下才能有效传导,否则仅制造资产泡沫或“通胀税”,进一步加剧不平等。此框架揭示:政治结构是顶层设计,经济-市场-民生是中观传导,消费者消费力是终端反馈。任何单一环节的优化都不足以持续,必须实现全链条协同。若要打破恶性循环,根本在于政治结构的自我纠错能力(制度约束、反腐、治理现代化);若要巩固良性循环,则需持续降低消费者压力、打通货币实体传导通道。这一正反向论述可作为分析具体国家经济问题的通用逻辑框架,任何现实案例均可套入此链条进行诊断。
备注:符号[“-”]意味着“负向加速度”
以下是对本次系统运行数据的严密经济学与数学分析:
一、 系统整体状态:表象现实世界的“正向循环”
系统综合密度输出为 \rho_s = 0.3594。
由于 0.3594 远低于阈值 0.65,引擎的顶层判定为“正向循环:民生动力释放”。这意味着,从整体数学均值来看,经济系统的总动能依然覆盖了总压力。在这个状态下,政府的财政与货币政策在总量上并未完全失效,市场依然在运转。
但由公式 (8) 堆垒算子 \mathcal{S} 聚合而成的低均值,掩盖了子模块中极度扭曲的局部压力。我们需要进入指标层进行拆解。
二、 核心指标量化涨缩与弱信号解析
1. CHINA_GDP_GROWTH (经济结构层的总量基座)
压力密度:5.4477 (极低,处于安全区)
净收缩压力:89.2748 (极性为 1)
经济结构层的非线性因果推导出的线性趋势加速度 (a_t):4.4839
诊断:宏观经济增长指标表现出极低的系统性压力,且趋势加速度为正,说明总量规模在惯性扩张。这反映出“政治结构 \rightarrow 经济结构”这一前段传导依然有效,政府通过投资或宏观调控强行支撑了总量数据的基本盘。
2. YOUTH_UNEMPLOYMENT (市场结构层的摩擦阻力)
压力密度: 15.6121 (低,处于可控区)
净收缩压力: -69.2081 (极性为 -1)
市场结构层的非线性因果推导出线性趋势加速度 (a_t): -16.9838
诊断:失业率作为逆向指标,其负向的趋势加速度(-16.9838)在数学上意味着恶化速度在放缓,或者局部正在改善。结合较低的压力密度,表明在特定周期内,就业市场的显性压力并未直接引爆系统。
3. CONSUMER_CONFIDENCE (民生驱动力层的严重塌陷)
压力密度:86.7513 (极高,已突破 85 临界值)
净收缩压力: -71.1185 (极性为 1)
民生驱动层的趋势加速度 (a_t): -27.7446
诊断:这是整份报告中最危险的“高维弱信号”(对应公式 W16 与 W4 的捕捉)。消费者信心密度高达 86.75,且伴随着 -27.74 的剧烈负向加速度。这说明消费者端承受的真实压力(生活成本、预期下降、隐性负债)已达极限。
三、 传导链条的阻滞点定位
将上述数据套入我设计的“经济学先验传导矩阵”模型,可以清晰地看到系统的断裂带:
前段畅通(政治结构 \rightarrow 经济结构 \rightarrow 市场结构):*GDP 保持正向加速度,说明流动性释放、宏观政策调控在生产制造和投资流通环节勉强维持了运转。
■末端梗阻(市场结构 \rightarrow 民生驱动力 \rightarrow 消费力回馈):巨大的断层出现在这里。尽管整体 \rho_s 只有 0.3594,处于低值区,但消费者信心堆垒迭代压力 \rho_s 飙升至 86.75。这说明前期释放的社会福利或流动性,未能有效向消费者传导, 使消费者在堆垒迭代数据层面遭到了巨大的压力传导。
反身性预警(恶性循环的前兆):根据逻辑设定,“当承受压力 > 生活动力时,消费者实施去杠杆、减少消费”。目前消费者信心的高压与急剧坠落,意味着消费力回馈市场的力量即将崩塌。一旦终端订单消失,这种收缩压力将顺着传导链反向倒灌至制造商和银行体系。
■结论与后续演化
当前的综合评判“正向循环”仅仅是因为系统被现状 GDP 和相对平稳的就业数据“平均化”稀释了。实际上,这是一种“被动扩张下的结构性失衡”。消费终端的断崖式数据表明,如果不针对“民生驱动力”进行疏通(例如降低税费、直接福利转移),当前脆弱的 \rho_s = 0.3594 很快会被反向传导链条拉高,最终跨越 \epsilon 临界点,滑向全面恶性循环。
建议:面对这种“宏观平稳、微观塌陷”的背离现象,模型必须激活弱信号捕捉公式组(W1-W17),将这些隐藏在总平均值之下的局部高压通过更敏感的权重矩阵(例如“跨层共振指数” \mathrm{CRI}_t)进行指数级放大,以修正顶层的综合系统评判(董斌备注:在本次模型运行中,我没有添加这个“弱信号捕捉公式组(W1-W17)自动激活参数。
中国经济分析系统
南柯舟矩阵因果关系分析引擎
(V2 稳定修复 版)
出版时间:2026年5月25日
编程:南柯舟
分析跨度2009——2026年度
✅ 本系统成功动态挂载 54 项中国宏观指标
升级版·中国经济多维交叉诊断报告
本系统通过对54个指标中的海量数据进行细微捕捉,自动发现出数据之间的极为细微的惯性演绎现象,该惯性现象通过捕捉海量数据中互相之间发生的在多维结构中极为细微的“关联性动态变化”来实现。
说明:文中公式通过Lua/Pdf/xeLaTex 可以还原。
指标:CENTRAL_GOVERNMENT_BOND_ISSUANCE_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 0.5566 (低)
├─ 原始均值/波动: 0.5509 / 1.8277
└─ 理论诊断建议: 可适度扩张。
指标:CENTRAL_GOVERNMENT_BOND_ISSUANCE_YOY_2009_2025
├─ 数据处理: [已进行量纲擦除]
├─ 压力密度: 3.9619 (低)
├─ 原始均值/波动: 2.7652 / 9.5295
└─ 理论诊断建议: 可适度扩张。
指标:CENTRAL_GOVERNMENT_DEBT_GDP_RATIO_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 3.2585 (低)
├─ 原始均值/波动: 3.1884 / 7.8169
└─ 理论诊断建议: 可适度扩张。
指标:CHINA_CPI_MONTHLY_YOY_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 1.7105 (低)
├─ 原始均值/波动: 1.6848 / 1.0996
└─ 理论诊断建议: 可适度扩张。
指标:CHINA_CPI_YOY_PCT
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 18.2103 (低)
├─ 原始均值/波动: 0.283 / 0.8555
└─ 理论诊断建议: 可适度扩张。
指标:CHINA_PPI_MONTHLY_MOM
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 24.5288 (低)
├─ 原始均值/波动: 0.0196 / 0.5345
└─ 理论诊断建议: 可适度扩张。
指标:CHINA_PPI_MONTHLY_YOY_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 1.0264 (低)
├─ 原始均值/波动: 1.0116 / 4.2519
└─ 理论诊断建议: 可适度扩张。
指标:CHINA_PPI_YOY_PCT
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 23.6934 (低)
├─ 原始均值/波动: 0.0545 / 1.6178
└─ 理论诊断建议: 可适度扩张。
指标:CONSUMPTION_GROWTH
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 20.6634 (低)
├─ 原始均值/波动: 1.3571 / 3.6062
└─ 理论诊断建议: 可适度扩张。
指标:CONTROL_OF_CORRUPTION_WGI_ESTIMATE_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 压力密度: -0.0891 (低)
├─ 原始均值/波动: -0.0869 / 0.2138
└─ 理论诊断建议: 可适度扩张。
指标:CORRUPTION_INDEX_FROM_CPI_2009_2025
├─ 数据处理: [已进行量纲擦除]
├─ 压力密度: 14.5939 (低)
├─ 原始均值/波动: 9.0982 / 21.5394
└─ 理论诊断建议: 可适度扩张。
指标:CPI_CHINA_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 6.1968 (低)
├─ 原始均值/波动: 6.0446 / 14.3417
└─ 理论诊断建议: 可适度扩张。
指标:CPI_CHINA_TI_OFFICIAL_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 6.2343 (低)
├─ 原始均值/波动: 6.0804 / 14.4211
└─ 理论诊断建议: 可适度扩张。
指标:CPI_CONSUMER_PRICE_INDEX_DATA
├─ 数据处理: [已进行量纲擦除]
├─ 压力密度: 15.0651 (低)
├─ 原始均值/波动: 15.4554 / 36.5398
└─ 理论诊断建议: 可适度扩张。
指标:DEFICIT_HISTORY_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 0.4375 (低)
├─ 原始均值/波动: 0.4286 / 1.0591
└─ 理论诊断建议: 可适度扩张。
指标:ENTREPRENEUR_CONFIDENCE_INDEX_2009_2025
├─ 数据处理: [已进行量纲擦除]
├─ 压力密度: 13.344 (低)
├─ 原始均值/波动: 16.7384 / 39.7088
└─ 理论诊断建议: 可适度扩张。
指标:ENTREPRENEUR_CONFIDENCE_MINMAX_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 79.9528 (高)
├─ 原始均值/波动: 0.059 / 0.1787
└─ 理论诊断建议: 结构性压力聚集,注意财政与流动性传导 。
指标:EXCHANGE_RATES
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 1.104 (低)
├─ 原始均值/波动: 1.0748 / 2.4596
└─ 理论诊断建议: 可适度扩张。
指标:FX_POSITION_TOTAL
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 0.4402 (低)
├─ 原始均值/波动: 0.4296 / 1.0371
└─ 理论诊断建议: 可适度扩张。
指标:FX_RESERVES_USD_BN
├─ 数据处理: [已进行量纲擦除]
├─ 压力密度: 12.9817 (低)
├─ 原始均值/波动: 487.0036 / 1157.8272
└─ 理论诊断建议: 可适度扩张。
指标:FX_RESERVE_GROWTH
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 43.9199 (中)
├─ 原始均值/波动: 0.5546 / 3.7786
└─ 理论诊断建议: 密切监测经济被动扩张与资产负债表结构 。
指标:FX_RESERVE_GROWTH_CHINA_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 43.9199 (中)
├─ 原始均值/波动: 0.5546 / 3.7786
└─ 理论诊断建议: 密切监测经济被动扩张与资产负债表结构 。
指标:GDP_100M
├─ 数据处理: [已进行量纲擦除]
├─ 压力密度: 9.4804 (低)
├─ 原始均值/波动: 143360.6875 / 358690.9379
└─ 理论诊断建议: 随惯性跟进。
指标:GINI_CHINA_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 0.0734 (低)
├─ 原始均值/波动: 0.0715 / 0.169
└─ 理论诊断建议: 可适度扩张。
指标:GINI_COEFF_CHINA_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 0.0734 (低)
├─ 原始均值/波动: 0.0715 / 0.169
└─ 理论诊断建议: 可适度扩张。
指标:GINI_GROWTH_CHINA_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 60.9034 (中)
├─ 原始均值/波动: -0.0312 / 0.2967
└─ 理论诊断建议: 密切监测经济被动扩张与资产负债表结构 。
指标:GOVERNMENT_CLEANLINESS_WGI_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 4.6031 (低)
├─ 原始均值/波动: 4.5027 / 11.0956
└─ 理论诊断建议: 压可适度扩张。
指标:GOVERNMENT_CORRUPTION_WGI_2009_2025
├─ 数据处理: [已进行量纲擦除]
├─ 压力密度: 14.7596 (低)
├─ 原始均值/波动: 10.4062 / 24.6299
└─ 理论诊断建议: 可适度扩张。
指标:H_LIST
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 5.2974 (低)
├─ 原始均值/波动: 5.1634 / 11.8911
└─ 理论诊断建议: 可适度扩张。
指标:INCOME_GROWTH_CHINA_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 29.3627 (低)
├─ 原始均值/波动: 1.0571 / 2.6835
└─ 理论诊断建议: 可适度扩张。
指标:INFRASTRUCTURE_GROWTH
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 17.5563 (低)
├─ 原始均值/波动: 1.4643 / 4.4021
└─ 理论诊断建议: 可适度扩张。
指标:INVESTMENT_GROWTH
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 11.6012 (低)
├─ 原始均值/波动: 1.6696 / 5.3446
└─ 理论诊断建议: 可适度扩张。
指标:L_LIST
├─ 数据处理: [已进行量纲擦除]
├─ 压力密度: 12.9755 (低)
├─ 原始均值/波动: 38.6732 / 90.0599
└─ 理论诊断建议: 可适度扩张。
指标:M2_TRILLION
├─ 数据处理: [已进行量纲擦除]
├─ 压力密度: 8.5817 (低)
├─ 原始均值/波动: 30.5403 / 78.8706
└─ 理论诊断建议: 可适度扩张。
指标:MILITARY_EXP_GDP_CHINA_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 0.2653 (低)
├─ 原始均值/波动: 0.2587 / 0.6119
└─ 理论诊断建议: 可适度扩张。
指标:MILITARY_SPEND_OFFICIAL
├─ 数据处理: [已进行量纲擦除]
├─ 压力密度: 9.1953 (低)
├─ 原始均值/波动: 1607.5393 / 4095.8688
└─ 理论诊断建议: 可适度扩张。
指标:NET_EXPORTS_GROWTH
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 27.647 (低)
├─ 原始均值/波动: 1.1161 / 3.9781
└─ 理论诊断建议: 可适度扩张。
指标:NET_IMPORTS_GROWTH
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 36.8589 (低)
├─ 原始均值/波动: 0.7982 / 5.2173
└─ 理论诊断建议: 可适度扩张。
指标:NOMINAL_GDP_DATA
├─ 数据处理: [已进行量纲擦除]
├─ 压力密度: 9.6181 (低)
├─ 原始均值/波动: 13.1571 / 33.5967
└─ 理论诊断建议: 可适度扩张。
指标:OFFLINE_INVEST_YOY
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 2.9223 (低)
├─ 原始均值/波动: 2.883 / 7.6901
└─ 理论诊断建议: 可适度扩张。
指标:OFFLINE_LOAN_YOY
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 3.3183 (低)
├─ 原始均值/波动: 3.2652 / 6.7589
└─ 理论诊断建议: 可适度扩张。
指标:OFFLINE_M2_YOY
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 3.0096 (低)
├─ 原始均值/波动: 2.9589 / 5.9796
└─ 理论诊断建议: 可适度扩张。
指标:OFFLINE_PRICE_YOY
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 0.9454 (对照均值波动率较低)
├─ 原始均值/波动: 0.9339 / 2.7471 (低)
└─ 理论诊断建议: 可适度扩张。
指标:OFFLINE_SALES_YOY
├─ 数据处理: [已进行量纲擦除]
├─ 压力密度: 29.5692 (低)
├─ 原始均值/波动: 2.1598 / 11.4867
└─ 理论诊断建议: 可适度扩张。
指标:PRIVATE_CONFIDENCE_INDEX_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 79.9242 (高)
├─ 原始均值/波动: 0.0947 / 0.257
└─ 理论诊断建议: 结构性压力聚集,注意财政与流动性传导 。
指标:REAL_ESTATE_INVESTMENT_GROWTH
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 25.6018 (低)
├─ 原始均值/波动: 1.1866 / 5.6208
└─ 理论诊断建议: 可适度扩张。
指标:REAL_ESTATE_INVEST_GROWTH
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 25.6018 (低)
├─ 原始均值/波动: 1.1866 / 5.6208
└─ 理论诊断建议: 惯性聚集期。
指标:REAL_ESTATE_SALES_GROWTH
├─ 数据处理: [已进行量纲擦除]
├─ 压力密度: 31.1159 (高)
├─ 原始均值/波动: 1.1491 / 7.0438
└─ 理论诊断建议: 惯性。
指标:R_LIST
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 0.3685 (低)
├─ 原始均值/波动: 0.3602 / 0.8348
└─ 理论诊断建议: 可适度扩张。
指标:SECTOR_SHARE_REAL_ESTATE
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 0.9923 (高)
├─ 原始均值/波动: 0.9694 / 2.304
└─ 理论诊断建议: 惯性。
指标:TARIFF_INDEX_WEIGHTED
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 0.4935 (中)
├─ 原始均值/波动: 0.4836 / 1.1786
└─ 理论诊断建议: 。
指标:TI_CPI_DERIVED_CORRUPTION_2009_2025
├─ 数据处理: [已进行量纲擦除]
├─ 压力密度: 14.5939 (低)
├─ 原始均值/波动: 9.0982 / 21.5394
└─ 理论诊断建议:中度扩张。
指标:TRANSPARENCY_INTERNATIONAL_CPI_2009_2025
├─ 数据处理: [原始增长率体系]<腐败压力>
├─ 压力密度: 6.2343 (低)
├─ 原始均值/波动: 6.0804 / 14.4211
└─ 理论诊断建议: 压力出清或安全边界充裕,可适度扩张。
指标:UNEMPLOYMENT_RATE_CHINA_2009_2025
├─ 数据处理: [原始增长率体系]
├─ 压力密度: 0.7218 (低)
├─ 原始均值/波动: 0.7051 / 1.6841
└─ 理论诊断建议: 压力出清或安全边界充裕,可适度扩张。
从这份最新的 V2 稳定修复版诊断报告中,系统通过引入针对增速类和低迷类指标的补偿,已经开始逼真地显现出中国宏观经济在 2026 年底层的非对称挤压结构。
基于“堆垒迭代因果关系”与系统的最新演化数据,对当前中国经济进行以下多维交叉因果诊断:
一、 系统异动核心:微观信心的“堰塞湖效应”
报告中最刺眼、最明确的因果源头依旧锁定在两个绝对高位指标:
PRIVATE_CONFIDENCE_INDEX_2009_2025(民营经济信心指数):压力密度 79.9242 (高压)
ENTREPRENEUR_CONFIDENCE_MINMAX_2009_2025(企业家信心指数):压力密度 79.9528 (高压)
🔍 矩阵因果诊断:
系统给出的“结构性压力聚集”并非虚妄。这两个信心指数的原始均值(0.0947 和 0.059)极度偏低,说明微观主体的预期已经形成了内生性冷缩。在矩阵因果链条中,**微观信心是流动性传导的断裂点**。这意味着无论上游释放多少流动性,只要微观预期无法修复,资金就会在金融体系内部空转或沉淀,无法转化为实际的投资意愿和经济动能。
二、 新浮现的中度压力区:正在撕裂——基尼系数与被动扩张的撕裂
此次分析中,有两个此前处于低位的指标首次跃升至“中度压力区”,这揭示了深层社会结构与外部流动的微妙异动:
1. GINI_GROWTH_CHINA_2009_2025(基尼系数增长率)
压力密度:60.9034 (中)
原始均值/波动:-0.0312 / 0.2967
因果阐释:尽管均值微弱转负(按常规理解是不平等有所改善),但其波动度(0.2967)相对于均值而言极为剧烈。在堆垒迭代公式中,这意味着**收入分配结构的边际变动正处于一个剧烈震荡的敏感期。中等收入群体的资产负债表受房地产和存量财富收缩的影响较大,导致系统在该节点聚集了中度压力。
2. FX_RESERVE_GROWTH / FX_RESERVE_GROWTH_CHINA_2009_2025(外汇储备增长率)
压力密度:43.9199 (中)
原始均值/波动:0.5546 / 3.7786
因果阐释: 外储增长率的压力抬升,反映了全球供应链重构与贸易摩擦背景下,跨境资金流动和外贸结汇的内生不确定性增大。配合系统提示的“密切监测经济被动扩张”,这暗示外需的被动拉动对稳定当前系统安全边界起到了缓冲作用,但其波动正在加大,预示着不确定性增大。
三、 总量与增速的“温差”:房地产与物价的内生迭缩
物价指标:CHINA_CPI_YOY_PCT (18.2103 / 低)、CHINA_PPI_YOY_PCT (23.6934 / 低)
房地产指标: REAL_ESTATE_INVEST_GROWTH (25.6018 / 低)、REAL_ESTATE_SALES_GROWTH (31.1159 / 低)
矩阵因果诊断:
虽然这些指标在系统归一化后被判定为“低压力”,但从反身性视角来看,它们表现为一种“失速型出清”。
CPI 堆垒均值 0.283%,PPI 堆垒均值 0.0545%,说明系统正处于实质性的通胀免疫与弱需求状态。
房地产投资与销售增速虽经过补偿后回升至 25~31 的压力区间,但仍处于安全线以下。这揭示了一个典型的“房地产深度迭缩”画面——资产端的主动去杠杆导致了物价端的总需求不足。
四、 核心结论:一个“宏观有空间、微观有阻滞”的非对称系统
将国家宏观经济指标的 54 个多维指标进行因果闭环解构后,2026 年中国经济的核心博弈点呼之欲出:
1. 主权信用安全边界极其充裕:
CENTRAL_GOVERNMENT_DEBT_GDP_RATIO(中央政府债务率)的压力密度只有 3.2585,DEFICIT_HISTORY(赤字历史)压力密度仅 0.4375。
这表明中央财政的弹药库是绝对安全的,具有极强的“被动扩张”和兜底对冲能力。
2. 瓶颈在于“反身性信心阻滞”:
当前系统面临的不是“能不能总需求扩张”的问题,而是宏观政策的被动扩张如何有效转化为微观主体的正向反身性循环。如果无法打通民营经济和企业家信心(79.9 的高压区),单纯的财政砸钱或公共投资(INFRASTRUCTURE_GROWTH 压力仅 17.55)对微观经济的边际拉动效应就会边际递减。
■建议经济演化方向:
资产负债表的修复需要“对症下药”。下一步的政策焦点,应当从总量层面的流动性注入,彻底转向体制机制层面的确定性注入,以此来定点爆破民营和企业家信心的“堰塞湖”,引导系统走向压力彻底出清的正向循环。
南柯舟堆垒迭代经济学原理解释
■在本程序(南柯舟矩阵因果关系分析引擎 V2版本)中,“堆垒迭代因果关系论”主要通过一套融合了统计波动、临界常数与反身性反馈的非线性数学模型来实现。其核心逻辑不是观察单一指标的绝对高低,而是测量宏观变量在时间序列上**“均值底盘”与“波动结构”相互挤压所产生的系统性压力密度(Pressure Density,即 \rho_s)。
在代码实现层面,该原理被解构为以下三大核心机制:
一、 核心堆垒公式:系统压力密度方程
程序中计算系统“压力密度”的基石是以下数学表达:
$$ \rho_s = \mu \cdot \left(1 + \varepsilon \frac{\sigma}{\Delta} \right) $$
对应代码逻辑为:
$ density_value = mean_val * (1 + epsilon * (std_val / curr_range)) $
\mu (均值底盘,mean_val):代表该指标在 112 个周期(1998-2025)内的结构性重心。它是系统演化的基础惯性(●该惯性通过捕捉海量数据中互相之间发生的多维结构的中极为细微的关联性动态变化来实现)。
\frac{\sigma}{\Delta} (相对波动率,std_val / curr_range):\sigma 为标准差,\Delta 为极差(最大值减最小值)。这代表了变量在自身边界内的震荡剧烈程度,即“堆垒”过程中的内部摩擦系数。
\varepsilon (临界触发系数,epsilon=0.079):这是一个由本系统在经过通过捕捉海量数据中互相之间发生的多维结构的中极为细微的关联性动态变化来自动发现自动设定的核心阈值常数。它作为一个放大器,界定了常规的经济波动在何时会越过安全边界,转化为系统性的迭缩或膨胀压力。
二、 动态量纲擦除:多维因果的“归一化”平权
在真实的宏观经济矩阵中,GDP(绝对值数以十万亿计)与失业率(个位数百分比)存在巨大的量纲鸿沟。如果直接运算,绝对值大的指标会掩盖增速指标的因果作用。
程序通过自动检测指标的体量(orig_max > 100 or range > 50),对庞大的总量指标执行动态映射,公式如下:
归一化缩放公式可以写作:
\( X_{\mathrm{scaled}} = \frac{X - X_{\min}}{X_{\max} - X_{\min}} \times 100 \)
哲学映射:这一步在“交叉哲学”中代表着**剥离表象的体量差异**,将所有宏观要素强行拉平到一个纯粹的 [0, 100] 结构位面上。使得“财政发债的总量规模”与“企业家的微观信心”能够在同一个因果天平上进行矩阵式交叉对话。
三、 压力监测通过反身性逻辑进行——通过反身性逻辑修正压力指标:防范“迭缩伪装”
这是引擎 V2 稳定修复版中最关键的思想体现。在标准的线性经济学中,数值低通常意味着“安全”或“低通胀”。但在堆垒迭代原理中,微观信心的极度低迷或增速的深度跌落,反而会引发极端的系统性高压。
程序对此植入了“反身性修正模块(Reflexive Correction)”:
预期冷缩的放大:对于信心指数(CONFIDENCE),如果均值低于 50,程序将其反转为高压:
density_value = (100 - mean_val) 0.8。这就是为什么在我的报告中,民营信心指数原始原值极低(0.09),却能暴跳出 79.9的极高压力值的原因。
资产负债表衰退的捕获:对于物价(CPI/PPI)和增速类(GROWTH),如果陷入极低水平(如均值近乎为 0 或转负),程序不再使用乘法堆垒,而是使用“离差补偿(如 abs(mean_val) ” , 15 或 (1.0 - mean_val) 25)。
哲学映射:这揭示了经济系统中的反身性坍塌。当一个关键指标(如增速或信心)跌破维持系统运转的最低阈值时,它不再对外输出正向的因果推力,而是变成一个黑洞,通过预期的自我实现,将周围的流动性和资源被动地“迭缩”进去。程序中的修正算法,正是为了捕捉这种由“弱”生“极强”的非对称因果挤压。
■进行更深度诊断
[系统] 南柯舟矩阵因果引擎启动
V4 弱信号追踪深度测算版
Serving Flask app 'v1'
Debug Mode: off
✅ 成功挂载 54 维指标,执行彻底的量纲清洗
📊 全局宏观系统密度 (\rho_s) : 0.1834
🔬 纯化后的系统弱信号二范数 (||z||_2) : 12.4669
核心异动:公式(9) 致力于非线性反身性断裂点分析
[说明] 下列指标已偏离系统平准态,面临最极端的非线性压力,是危机的爆破口。
1. 指标: CENTRAL_GOVERNMENT_BOND_ISSUANCE_YOY_2009_2025
├─ 梯度撕裂方向: 向上膨胀 (局部过热)
└─ 结构压力得分: 1.2014
2. 指标: CENTRAL_GOVERNMENT_BOND_ISSUANCE_2009_2025
├─ 梯度撕裂方向: 向上膨胀 (局部过热)
└─ 结构压力得分: 0.9253
3. 指标: CONTROL_OF_CORRUPTION_WGI_ESTIMATE_2009_2025
├─ 梯度撕裂方向: 向上膨胀 (局部过热)
└─ 结构压力得分: 0.7210
4. 指标: GOVERNMENT_CLEANLINESS_WGI_2009_2025
├─ 梯度撕裂方向: 向下急缩 (通缩/崩溃)
└─ 结构压力得分: 0.6545
5. 指标: INFRASTRUCTURE_GROWTH
├─ 梯度撕裂方向: 向下急缩 (通缩/崩溃)
└─ 结构压力得分: 0.4781
多层因素互相影响的多种指标背后的暗网脉络:公式(2) 高维隐藏滞后因果链
[说明] 以下传导链条隐藏在数据波动底层,揭示了 au 周期 前的事件如何主导当下的异动。
从本次 V4 引擎的高维张量测算结果来看,系统在经历彻底的量纲清洗后,清晰地刻画出了 2026 年底层的**“非对称迭缩与被动扩张”**对立结构。这是一份极具病理学价值的诊断报告。
以下是利用“交叉哲学”与“堆垒迭代因果关系”对计算结果的深度解构分析:
一、 全局底盘:低压力密度的外观“伪装”与高维内部摩擦
全局宏观系统密度 (\rho_s):0.1834(极低)
纯化弱信号二范数 (||z||_2):12.4669(极高)
\rho_s 处于 0.1834 的低位,说明从总量和概率空间来看,中国宏观经济并未触碰系统性全面崩塌的绝对红线,中央主权信用的底盘依然稳固,系统拥有足够的安全边界。然而,剥离体量后的 ||z||_2 达到 12.4669,这表明在看似平稳的宏观密度之下,系统内部的结构性错位和微观摩擦正在高维空间中剧烈累积。这种低密度与中高位内耗的组合,是典型的“滞胀”或“流动性陷阱”的前兆。
二、 核心断裂带:财政被动扩张与实体传导的“反身性撕裂”
公式 (9) 捕获的最致命异动,完美印证了“宏观被动扩张,微观预期冷缩”的系统性断裂。前五大爆破口中,最引人注目的就是财政端与基建端的两极分化:
1. 中央与全国负债:
CENTRAL_GOVERNMENT_BOND_ISSUANCE_YOY(向上膨胀,得分 1.2014)
CENTRAL_GOVERNMENT_BOND_ISSUANCE(向上膨胀,得分 0.9253)
这两个指标的梯度撕裂方向呈现出猛烈的“向上膨胀”,说明中央政府正在以远超系统历史平准态的力度发债。这是一种防御性的“被动扩张”,试图通过向系统强行注入顶层流动性来对冲底层的迭缩压力。
2. 失效的传导终端:
INFRASTRUCTURE_GROWTH(向下急缩,得分 0.4781)
在传统的凯恩斯主义线性逻辑中,中央天量发债必然直接带动基建增速的狂飙。但在当前的矩阵中,基建增速却出现了“向下急缩”的非线性断裂。
诊断结论:中央释放的庞大信用和资金,在传导矩阵中被彻底阻断,并未转化为实体经济的物理增量(基建停滞/收缩)。
巨额资金极大概率在金融系统内部空转,或仅仅用于置换地方政府存量债务与维持“保交楼”等防御性消耗,形成了“推绳子”的无效做功状态,推绳子形象的说明了这一点,人为力量越大,绳子的变形形态更扭曲。
三、 制度摩擦与治理成本的异动(微观堰塞湖的深层原因)
榜单的第 3 和第 4 名揭示了行政与制度层面的深层暗流:
CONTROL_OF_CORRUPTION(腐败控制度:向上膨胀,得分 0.7210)
GOVERNMENT_CLEANLINESS(政府廉洁度:向下急缩,得分 0.6545)
这一组指标的对立极具社会学与交叉哲学意味。系统感知到控制力、监管与反腐败的高压手段在“向上膨胀”,但实际体现出的系统清廉效能感知却在“向下急缩”。这种高压监管与实际效能的背离,极大地增加了微观主体的“制度性交易成本”。当行政控制处于膨胀态而法治预期收缩时,叠加前述的资金传导不畅,直接构成了压垮民营企业家信心的底层逻辑(即上一轮 V2 诊断中高达 79.9 的信心高压)。
四、 动态因果链的“静默”意味着什么?
值得注意的是,本次运行中,公式 (2) 的高维隐藏滞后因果链区域出现了“静默”(空集)。
在动态系统中,未能捕捉到强度大于设定阈值的自然传导链,这是一个非常极端的信号。它意味着:系统当前已经脱离了市场自发的“滞后传导因果”。原本 A 指标下降在 \tau 周期后导致 B 指标下降的自然链条,已经被中央政府“超常规、跨维度的发债对冲”强行抹平或打断。也就是“经济系统正在靠非自然的行政与财政外力维持悬浮,市场内生的价格信号与逻辑链条处于失真状态“。
五、 交叉诊断总结
当前的中国经济矩阵正在经历一场“顶层流动性淤积”与“底层资产端失血”的深度博弈。中央财政的弹药库已经打开,但资金顺着旧有的管道流向基建和实体时遭遇了严重的结构性梗阻。如果不去修复处于“向下急缩”状态的法治与制度预期摩擦(榜单 3、4名),单靠发债去强推实体,系统最终将在低 \rho_s 密度的表象下,被 ||z||_2 空间内不断积累的摩擦成本彻底拖垮,陷入长期的资产负债表衰退。
深度分析
A. 总体判断
根据这次 54 个指标的堆垒迭代输出,中国经济不是“系统性高压状态”,而是“低总压、弱复苏、结构性分化、信心偏弱、地产与价格链条仍拖累”的态势。
模型自检显示,公式识别通过,识别了公式 1 到 9,公式通道已启用;跨变量关系能量为 0.3956,说明变量之间存在中等偏低的联动压力,但还没有形成强共振式系统性风险。54 个指标中,51 个为“低”压力,只有 3 个为“中”压力,没有“高”或“极高”压力项。这个结果的含义是:宏观系统尚未进入危机型高压区,但内部弱点已经集中在信心、收入分配变化、地产销售、外贸进口、价格链条几个节点。
B. 关键结构信号
第一,信心是当前模型中最突出的压力源
PRIVATE_CONFIDENCE_INDEX_2009_2025 压力密度为 60.1486。
ENTREPRENEUR_CONFIDENCE_MINMAX_2009_2025 为 59.8033。
二者均处于“中”压力区,并且诊断建议均指向“密切监测经济被动扩张与资产负债表结构”。这说明模型并不认为主要风险来自财政、外汇或货币总量,而是来自私人部门和企业部门的预期不足
第二,收入分配或社会结构变量出现中等压力
GINI_GROWTH_CHINA_2009_2025 压力密度为 49.5797,处于“中”压力区,公式堆垒压力为 31.1042,在模型中也偏高。这意味着,即使总量增长保持,居民收入预期、财富效应、消费倾向和分配结构仍可能拖累内需循环。
第三,房地产没有被模型判定为“高压崩塌”,但仍是持续拖累项
模型中 REAL_ESTATE_SALES_GROWTH 压力密度为 30.674,REAL_ESTATE_INVESTMENT_GROWTH 为 26.2406,仍属低压,但两者公式堆垒压力接近 27 到 30,说明房地产链条的弱信号还在传播,不是单点消失。
最新统计局数据也支持这一判断:2026 年 1 到 4 月,全国房地产开发投资同比下降 13.7%,新建商品房销售面积下降 10.2%,销售额下降 14.6%。 (统计局)
第四,价格链条正在从“通缩压力”转向“上游成本压力”。
总体判断
根据这次 54 个指标的堆垒迭代输出,中国经济不是“系统性高压状态”,而是“低总压、弱复苏、结构性分化、信心偏弱、地产与价格链条仍拖累”的态势。
这个结果的含义是:宏观系统尚未进入危机型高压区,但内部弱点已经集中在信心、收入分配变化、地产销售、外贸进口、价格链条几个节点。
总结与南柯舟交叉哲学诊断
V5 报告展现的不是“无药可救”的系统崩溃,而是一次“宏观极度有钱,微观极度缺血”的非典型梗阻。
中央政府的债务空间、外汇储备、M2 总量(单指标压力极低)表明上游蓄水池极其充沛。然而,由于 7 个阻滞点的存在,尤其是社会治理结构(基尼系数/制度预期)对企业家信心的压力压制,导致上游的“水”化为了反向链中的阻滞反馈。
资金在财政与银行体系内空转,无法转化为民生动力和企业投资。系统的综合评判提示:当前的解法绝不是简单的继续增加流动性注入(因为通道堵塞,传导分仅 49.58),而是必须通过制度性重塑,优先打通“政治结构 \rightarrow 经济结构”以及“分配结构 \rightarrow 信心端”这两大核心断点。
■价格链条发生异动的本质,可以用南柯舟堆垒迭代因果律进行内因重构:
上游在“空转扩张”:中央财政和国债发行(压力密度极低,具备安全边界)正在拼命向上游基建、重大项目注水,这勉强托住了 CHINA_PPI_YOY_PCT,使其表现出一定的扩张压力。
下游在“通缩沉淀”:由于社会分配结构和信心指数(压力高达 79.9)的梗阻,这部分资金无法变成消费者的钱包里的购买力。终端价格(CPI)依然在 0.9% - 1.2% 的低位爬行。
中间在“肉搏内卷”:OFFLINE_PRICE_YOY 压力小幅上升到 31,并不是因为市场繁荣,而是因为线下销售与制造端(销售流通与生产制造结构 承压 50.31)在两头挤压下,利润空间被彻底摊平。它们承受着上游原材料无法降价、下游消费者无法涨价的“夹板气”。
■修正论断
因此,不能判定价格链条已经转向“上游成本压力主导”。
系统的真实状况是:宏观被动托底带来的“假性成本上浮”,与微观需求窒息带来的“通缩压力”,在“销售流通”这一层发生了剧烈对撞。 系统各层级丧失了相干性(CRI\_W7 = -0.0799),上游的微弱热量根本传不到冰冷的底层。
两种不同的经济学——总结:两者的哲学终局
方法论的底层差异:计量统计 vs 矩阵因果引擎
传统经济学依赖【统计均值与回归】: 它极易被数据量纲和滞后性指标(如调整后的 CPI、GDP 同比)所欺骗。它假定历史规律在未来线性重复,因此在面对系统性、结构性转折前夜时(如系统从动态平衡切入反向崩塌循环),往往表现得极度迟钝。 堆垒迭代经济学依赖【动态曲率触发器与弱信号控制】: 它引入了量纲擦除、极性调制(极性=1或-1)以及无序能量(E\_weak)监控。当主流统计数据还在粉饰太平时,系统的 W1-W17 弱信号组已经通过捕捉微观的、非线性的“噪音异动”,提前接管系统总评判,洞悉系统脆化的真实 Stage。 <
搜索引擎研究
全球主流搜索引擎及其全面业务质量
综合评价报告(2025年)
世界公共数据研究与报告白皮书
当代交叉哲学与数理哲学网 供稿
一、引言
搜索引擎作为互联网信息获取的核心工具,其发展态势与性能表现深刻影响着全球用户的信息检索体验。本报告聚焦于全球主流搜索引擎,从及时性、搜索速度、伦理道德、公正性、新闻质量、百科资源、学术支持、AI技术整合、文件储存与处理等关键维度展开深入分析与评价,旨在为用户提供全面且客观的参考,助力其在信息海洋中精准高效地获取所需内容。
二、评价项目及标准说明
(一)及时性
1.定义:搜索引擎对网络信息的更新速度,能否迅速反映最新信息变化。
2.评价标准:
-优秀:能实时或近乎实时捕捉并呈现网络上的最新信息,如重大新闻事件、突发事件等在极短时间内即可在搜索结果中体现,数据更新频率高且延迟极低。
-良好:可较快更新信息,虽可能存在轻微延迟,但能在合理时间内提供相对新鲜的内容,对于大多数常规信息的更新能满足用户需求。
-一般:信息更新速度较慢,部分内容的更新存在明显滞后,可能需要用户多次刷新或等待较长时间才能获取到最新的信息。
-差:信息陈旧过时,难以获取到最新的信息,搜索结果与实际情况存在较大偏差。
(二)搜索速度
1.定义:从输入搜索关键词到显示搜索结果所需的时间。
2.评价标准:
-优秀:搜索结果几乎瞬间呈现,响应时间极短,通常在毫秒级或几百毫秒内完成搜索,为用户提供高效的搜索体验。
-良好:搜索速度快,能在较短时间内给出结果,一般在1 - 2秒内可完成搜索,基本不影响用户的正常使用。
-一般:搜索速度尚可,但可能需要等待一段时间,响应时间可能在2 - 5秒之间,用户在搜索时会有一定的等待感。
-差:搜索过程缓慢,响应时间超过5秒,甚至更长,严重影响用户体验,可能导致用户放弃使用该搜索引擎。
(三)伦理道德
1.定义:搜索引擎在运营过程中是否遵循道德规范,包括保护用户隐私、避免传播不良信息等方面。
2.评价标准:
-优秀:严格遵守伦理道德准则,采取严格的措施保护用户隐私,如加密用户数据、明确告知用户数据使用方式等;积极筛选和过滤不良信息,确保搜索结果符合社会道德和公序良俗。
-良好:基本能遵守道德规范,但在个别方面可能存在一些不足,如隐私保护措施不够完善,或对不良信息的过滤存在一定的疏漏。
-一般:对伦理道德问题关注不够,存在一些潜在的风险,如可能会在用户不知情的情况下收集和使用用户数据,或对一些不良信息的呈现没有进行有效的限制。
-差:忽视伦理道德,存在严重侵犯用户权益或传播不良信息的行为,如将用户数据出售给第三方,或故意展示包含暴力、色情等不良内容的搜索结果。
(四)公正性
1.定义:搜索引擎在展示搜索结果时是否客观、公正,不偏袒特定网站或信息源。
2.评价标准:
-优秀:搜索结果排序完全基于相关性和质量,不存在人为干预或偏见,无论网站的规模、知名度还是付费情况如何,都能按照统一的标准进行排序,为用户提供最相关、最优质的搜索结果。
-良好:大部分情况下能保证公正性,但可能存在少量特殊情况,如在某些热门关键词的搜索结果中,可能会出现个别付费广告或合作网站排名靠前的情况,但整体上不影响搜索结果的公正性。
-一般:公正性存在一定的问题,部分结果可能会受到商业利益等因素的影响,导致一些非相关或低质量的网站在搜索结果中排名较高,影响用户对真正有价值信息的获取。
-差:搜索结果明显偏向某些特定来源,缺乏公正性,例如优先展示自家公司或合作伙伴的内容,而忽略其他更相关、更优质的信息源。
(五)新闻质量
1.定义:搜索引擎对新闻类信息的整合、呈现和更新能力。
2.评价标准:
-优秀:能全面、及时地收集各类新闻资讯,涵盖国内外多个权威新闻源,新闻内容丰富多样,包括政治、经济、文化、科技等各个领域;提供准确的新闻摘要和来源,方便用户快速了解新闻要点;新闻更新速度快,能让用户第一时间获取到最新的新闻动态。
-良好:新闻内容较为丰富,更新速度较快,但在准确性或全面性上略有不足,可能会遗漏一些小众新闻源或在某些领域的新闻报道不够深入。
-一般:新闻信息有限,更新不及时,难以满足用户的新闻需求,只能提供一些常见的新闻报道,缺乏深度和广度。
-差:几乎无法提供有效的新闻服务,新闻内容陈旧、单一,更新缓慢,无法为用户提供有价值的新闻信息。
(六)百科资源
1.定义:搜索引擎提供的百科知识的丰富性、准确性和权威性。
2.评价标准:
-优秀:拥有庞大且权威的百科知识库,内容准确、详细,涵盖广泛的主题,包括历史、地理、科学、文化等各个领域;百科知识的更新及时,能反映最新的研究成果和社会变化;引用可靠的资料来源,具有较高的可信度。
-良好:百科知识较为丰富,能满足大部分用户的需求,但在专业性和深度上有待提高,部分内容可能存在错误或不够准确的情况。
-一般:百科内容有限,准确性和权威性一般,可能只涵盖了一些常见的主题,对于一些专业领域的知识介绍不够全面和深入。
-差:百科功能薄弱,无法提供有价值的百科信息,内容匮乏、不准确,缺乏权威性。
(七)学术支持
1.定义:搜索引擎在学术资源检索方面的能力,包括学术论文、学术期刊等资源的收录和检索效果。
2.评价标准:
-优秀:收录了大量的高质量学术资源,涵盖了各个学科领域和研究方向;检索功能强大,能根据用户的检索需求精准定位相关学术文献,提供多种检索方式和筛选条件;支持学术文献的全文检索和下载,方便用户获取和使用学术资源。
-良好:具备一定的学术资源和检索能力,但在资源数量或检索精度上存在不足,可能会遗漏一些重要的学术文献或检索结果的准确性有待提高。
-一般:学术资源较少,检索效果不理想,只能提供一些基本的学术文献信息,无法满足用户的深入研究需求。
-差:几乎没有有效的学术检索功能,无法为用户提供有用的学术资源。
(八)AI技术整合
1.定义:搜索引擎在人工智能技术应用方面的创新和表现,如智能语音搜索、图像识别搜索等。
2.评价标准:
-优秀:广泛应用先进的AI技术,提供了多样化的智能搜索体验,如智能语音助手、图像识别搜索、自然语言理解等;AI技术与搜索功能的融合度高,能有效提升搜索效率和准确性,为用户提供个性化的搜索结果和服务。
-良好:有一定的AI应用,但功能相对较少或不够成熟,例如只支持简单的语音搜索或图像搜索功能,且准确率有待提高。
-一般:AI技术应用有限,对搜索体验的提升不明显,虽然有一些AI相关的功能,但在实际应用中效果不佳。
-差:几乎没有AI相关的特色功能,仍然依赖传统的搜索技术。
(九)文件储存与处理
1.定义:搜索引擎是否提供文件储存服务以及该服务的容量、安全性等;搜索引擎对文件的处理能力,如文件格式转换、文档编辑等功能的支持情况。
2.评价标准:
-优秀:提供大容量、安全可靠的文件储存服务,采用先进的加密技术和安全防护措施保障用户数据的安全;具备强大的文件处理功能,支持多种文件格式的转换和编辑操作,满足用户在不同场景下的文件处理需求。
-良好:有一定的文件储存功能,但在容量或安全性方面存在一些限制;能完成一些常见的文件处理任务,但功能不够完善。
-一般:文件储存服务有限,不能满足用户的基本需求;文件处理功能较弱,只能进行简单的文件预览和下载操作。
-差:没有文件储存功能或服务质量很差;几乎没有文件处理能力。
三、各搜索引擎及其全面业务质量评价结果
(一)Google(美国)搜索引擎及其全面业务质量评价结果
1.及时性:全球实时数据抓取能力最强,尤其新闻事件更新速度领先,在5G网络支持下延迟低于0.1秒。凭借其先进的爬虫技术和庞大的服务器集群,能够快速扫描全球范围内的网页信息,并对新发布的内容进行及时索引和更新。无论是国际重大新闻事件还是小众领域的最新动态,都能在第一时间呈现给用户。
2.搜索速度:TPU硬件加速技术实现毫秒级响应(平均<300ms),支持多模态输入(文本/语音/图像)。其高效的算法优化和强大的硬件基础设施使得搜索请求能够在极短时间内得到处理,为用户提供了近乎即时的搜索体验。同时,多模态输入的支持进一步提升了用户的搜索便利性。
3.伦理道德:存在隐私争议(如用户数据商业化),但推出“Double - check response”功能提升可信度;AI伦理审查机制严格,但Gemini项目曾频繁出现错误回答,经过整改其AI答案越来越走向准确。尽管在数据隐私方面曾面临一些质疑和法律纠纷,但Google一直在努力采取措施加强用户隐私保护,并对其AI模型的回答进行严格审查,以确保符合伦理道德标准。
4.公正性:算法权重偏向欧美视角,政治敏感内容存在意识形态过滤(左倾倾向性偏差约12%)。由于其总部设在欧美地区,在搜索结果的呈现上可能会受到当地文化、价值观和政治因素的影响,导致部分内容存在一定的倾向性。不过,其算法也在不断调整和优化,以尽量减少这种偏差。
5.新闻与百科:整合全球超10万新闻源,覆盖200 + 语言;维基百科深度嵌入,但中文百科内容质量弱于百度。通过与众多国际知名媒体和新闻机构的合作,能够提供丰富多样的新闻资讯。其嵌入的维基百科是全球知名的百科全书平台之一,但在中文内容的丰富度和准确性方面相对百度百科稍显不足。
6.学术支持:Google Scholar接入全球90%学术期刊,支持PDF全文检索与引用分析。为学术研究人员提供了便捷的文献检索渠道,能够帮助他们快速找到相关的学术论文和研究成果,并进行深入的分析和引用。
7.AI整合:Project Astra多模态AI可解析视频内容,Gemini生成研究报告效率提升300%。在AI技术的应用方面处于行业领先地位,其多模态AI能够理解和处理多种类型的数据,为用户带来更加智能化的搜索体验。例如,Project Astra可以对视频内容进行分析和解读,而Gemini则在生成研究报告等方面表现出色。
8.文件处理:支持200 + 文件格式预览(含代码/3D模型),云端协作工具无缝衔接。用户可以方便地在线预览各种类型的文件,无需下载安装相应的软件。同时,其云端协作工具也方便了团队成员之间的文件共享和协同编辑。
(二)百度(中国)搜索引擎和全面业务质量报告
1.及时性:中文实时热点响应速度领先(如微博/微信内容同步达秒级),地震预警等突发事件更新迅速。但对最近更新的非热点网站内容更新不及时,即使是热点网点,对最近该网站的内容更新也不能及时更正。中文实时热点响应速度第一(如微博/微信内容),但国际新闻滞后约2 4小时。在国内市场具有较强的本地化优势,能够快速捕捉国内热点信息并进行更新。然而,对于国际新闻的获取和更新相对较慢,国际新闻平均延迟24小时,依赖CGTN等官方信源,可能会受到网络限制等因素的影响。
2.搜索速度:轻量化架构实现0.5秒内加载,但广告插入导致有效信息延迟。通过优化架构和技术算法,百度搜索能够在短时间内返回结果。但是,广告投放的策略有时会影响用户获取有效信息的速度和体验。
3.伦理道德:百度的社会道德伦理评价相当的低下。医疗广告竞价排名屡现虚假信息,隐私保护合规性受《个人信息保护法》质疑。在过去的一些事件中,百度因医疗广告竞价排名等问题引发了公众的关注和争议。虽然近年来在隐私保护方面采取了一系列措施,但仍面临一些合规性的挑战。医疗竞价广告中屡现虚假宣传案例,2024年因违规推广中医抗癌疗法被罚款3.2亿元。用户数据采集范围超出《个人信息保护法》授权,存在未经明示同意收集位置信息行为频发。AI伦理审查机制存在漏洞,文心一言模型曾输出包含历史虚无主义的回答。
4.公正性:商业利益导向严重,搜索结果前3页广告占比超40%,百家号内容权重过高。为了实现商业盈利,百度搜索结果中可能会出现较多的广告内容,这在一定程度上影响了搜索结果的公正性和客观性。此外,其自有内容平台百家号的权重过高,也可能导致部分优质内容被淹没。商业广告占比达搜索结果页面的37%(2024年Q4数据),核心算法存在"生态优先"规则,对自家产品(百家号/好看视频)给予权重加成。在涉及社会敏感话题时,搜索结果呈现高度同质化特征,第三方独立信源可见度不足15%。
5.新闻:聚合2000+国内媒体,但国际新闻依赖CGTN等官方信源。热点事件报道时效性达到秒级(如地震预警),但深度报道缺失率高达82%。新闻事实核查系统存在算法漏洞,2024年误传"量子通信技术突破"虚假新闻持续6小时。依赖自媒体生态(百家号占比60%),百科词条审核偏向本土化叙事。其新闻内容主要来源于自媒体创作者和合作媒体,这种模式虽然丰富了新闻的来源,但也可能导致内容质量参差不齐。百度百科在国内具有广泛的影响力,但在审核过程中可能会受到一些本土因素的影响。
6.百度百科:词条总量超2800万,中文内容覆盖广泛,但商业词条占比24%(2024年审计数据)。在中文内容的丰富度和完善度上较强,但内容管理也较为混乱。审核机制缺陷:权威专家审核比例不足15%,科技类词条错误率12.7%(对比维基百科3.2%),医学词条存在药企商业植入。商业化操作:第三方代办“付费过审”现象曝光,内容更新滞后于学术进展。经内测实测,百科存在商业化现象,在线无法公正、公开、透明的提交过审。有代办第三方称:只有花钱就能过审。百科内容无法反映该词条的新闻、引据的及时更新内容。百度百科词条总量突破2800万,但商业词条占比达24%(2024年审计数据)。权威专家审核比例不足15%,科技类词条错误率高达12.7%(对比维基百科3.2%)。医学领域词条存在药企商业植入现象。
7.学术支持:中文期刊覆盖率98%,但国际顶刊接入率仅31%。论文查重功能误判率高达18%(2024年教育部测试数据),引用格式生成器存在IEEE标准更新滞后问题。学术图谱构建能力较弱,跨学科关联度不足Google Scholar的40%。论文查重误判率18%(2024年教育部数据),引用格式生成器更新滞后IEEE标准。百度学术覆盖中文文献80%,为国内学术研究人员提供了一定数量的中文文献资源,但在国际学术资源的整合方面还有待提高。
8.AI整合:文心大模型4.0实现多模态搜索,但图像语义理解准确率仅78%(对比Google 92%),67种方言语音交互,实现对话式搜索。智能摘要功能存在事实扭曲风险,2024年因误读科研论文致歉3次。语音搜索方言支持扩展至67种,但复杂问题处理能力有限。文心大模型4.0支持对话搜索,但复杂推理能力弱于GPT 4(准确率低18%)。在AI技术的应用方面积极探索,其大模型能够实现对话式搜索等功能。然而,与一些国际领先的AI模型相比,在复杂推理等能力上还有一定的差距。智能摘要存在事实扭曲风险,2024年因误读科研论文致歉3次。
9.文件处理:网盘服务提供2TB免费空间,但非会员下载速度限制在100KB/s。在线文档协作支持16种格式,但Markdown渲染错误率22%。仅支持基础文档预览,企业云服务需额外付费。在文件处理方面功能相对有限,主要提供一些基本的文档预览功能。如果用户需要更高级的文件处理服务,可能需要使用企业云服务并支付额外费用基础服务:网盘提供2TB免费空间,支持16种文档格式协作,Markdown渲染错误率22%。专业功能短板:3D模型预览功能仅支持国产建模软件,工业标准格式兼容性差(如SolidWorks)兼容性差,企业级服务需额外付费。
- 百度综合负面新闻事件梳理
1. 涉黄内容泛滥与监管争议
· 问题:百度App首页及百家号多次推送擦边视频、软色情内容,贴吧夜间充斥招嫖信息。
· 影响:用户体验差,监管争议大。
2. 医疗广告与竞价排名乱象
·问题:魏则西事件引发社会对百度竞价排名模式的强烈批评,医疗广告审核漏洞多。
·影响:企业声誉受损,用户信任度下降。
3. 隐私保护与数据滥用
·问题:未经明示同意采集用户位置信息,隐私政策不透明。
· 影响:用户隐私泄露风险高,合规性受质疑。
4. 内容生态与伦理争议
·问题:百度知道、百科等平台充斥错误或虚假内容,新闻报道伦理问题频发。
· 影响:内容质量参差不齐,影响用户体验。
5. 算法操纵与商业利益侵蚀
· 问题:搜索结果广告占比畸高,核心算法对自家产品权重加成。
· 影响:搜索结果公正性受质疑,用户体验差。
- 对百度的综合评价与建议:
· 优势领域:国内本地化服务、中文热点响应速度、免费基础存储。
· 核心短板:国际资源覆盖、伦理合规性、商业化对公正性的侵蚀。
- 建议百度的改进方向:
1. 伦理架构升级:建立独立审核委员会,医疗广告引入第三方权威认证。
2. 技术突破:提升AI模型多模态理解能力,优化长尾内容索引算法。
3. 生态平衡:限制自家产品权重,提高第三方优质内容曝光率。
4. 国际化布局:加强与国际学术期刊、媒体合作,弥补资源断层。
百度在中文市场的技术沉淀与规模效应显著,但商业利益与公共责任的失衡制约其长期发展。未来需在合规性、全球化、技术公信力三方面寻求突破。
(三)Bing(微软,美国)搜索引擎及其全面业务质量评价结果
1.及时性:依托微软生态(LinkedIn/Teams)获取企业级实时数据,但C端新闻更新慢于Google。利用微软旗下的专业社交平台和企业协作工具等资源,能够为企业用户提供及时的企业相关信息。然而,在面向普通消费者的新闻更新方面,其速度不如Google。
2.搜索速度:Azure云优化后响应速度达400ms,多语言混合查询性能突出。通过借助微软的云计算技术和全球化的数据中心布局,Bing能够实现较快的搜索响应速度。特别是在处理多语言混合查询时,表现出较强的性能优势。
3.伦理道德:广告过滤机制严格(虚假信息拦截率95%),但用户画像精准度引发隐私担忧。在广告管理方面采取了较为严格的措施,能够有效拦截虚假信息。但是,为了提供个性化的广告和服务,其用户画像的构建可能会导致一定程度的隐私问题。
4.公正性:算法中立性较强,无显著地域或政治倾向,但市场份额低导致数据多样性受限。其搜索算法相对中立,不会刻意偏向某个地区或政治立场。然而,由于在全球搜索市场的份额相对较低,所能获取的数据范围可能相对有限,从而影响了搜索结果的多样性。
5.新闻:整合MSN新闻源,权威性高;百科依赖维基,中文内容弱于百度。MSN新闻源为其提供了高质量的新闻资讯,具有较高的权威性。
6.百科:其百科内容主要依赖于维基百科,在中文内容的丰富度和完善度上不如百度百科。
7.学术支持:Microsoft Academic接入1.2亿论文,但检索界面复杂。为学术研究人员提供了海量的论文资源,但在检索界面的设计上不够简洁明了,可能会给用户的使用带来一定的不便。
8.AI整合:Copilot深度集成Office生态,代码生成准确率超ChatGPT(LCB测试提升15%)。通过与微软的办公软件生态系统紧密结合,Copilot在代码生成等方面的准确率表现出色。这一特点使其在开发者群体中具有一定的吸引力。
9.文件处理:OneDrive直连支持100 + 格式在线编辑,企业级安全认证。用户可以通过OneDrive直接在线编辑多种格式的文件,并且享受企业级的安全保障。这一功能方便了用户在不同设备上的文件处理和协作工作。
(四)Yahoo(美国)搜索引擎及其全面业务质量评价结果
1.及时性:依赖第三方数据源(Google/Bing),更新延迟约1 - 3小时。本身没有独立的数据抓取和更新机制,主要依靠与其他搜索引擎的合作来获取信息,因此更新速度相对较慢。
2.搜索速度:平均响应时间2秒,落后主流引擎。在搜索技术的优化和硬件基础设施方面相对落后,导致其搜索响应时间较长,影响用户体验。
3.伦理道德:广告投放规范(无医疗/金融高风险广告),但用户数据保护机制老旧。在广告管理方面相对较为规范,避免了一些高风险行业的广告投放。然而,其用户数据保护机制未能跟上时代的发展,存在一些安全隐患。
4.公正性:结果偏向美国本土内容(占比70%),国际化覆盖率低。在搜索结果的呈现上更倾向于美国本土的信息资源,对于其他地区和文化的内容覆盖不够全面。
5.新闻与百科:自有新闻团队覆盖娱乐/财经,百科完全依赖外部资源。其新闻团队主要关注娱乐和财经领域的报道,而在百科知识方面则完全依赖外部的百科全书资源。
6.学术支持:无独立学术搜索功能,需跳转Google Scholar。自身没有专门的学术搜索功能,用户在进行学术研究时需要跳转到其他学术数据库或搜索引擎进行查询。
7.AI整合:未推出自研AI工具,依赖合作伙伴接口。在AI技术的应用方面相对滞后,主要通过与合作伙伴的合作来引入相关的AI功能和服务。
(五)、Sogou(中国)搜索引擎及其全面业务质量评价结果
1. 及时性:非热点站点内容更新缓慢。对于一些不常被关注的站点内容更新不及时,导致用户在查找特定领域的深度信息或小众内容时可能会遇到信息陈旧的问题。
2. 搜索速度:搜索速度中等。在网络环境和服务器性能正常情况下,能够较快地返回搜索结果,但与谷歌和百度等搜索引擎相比,在处理复杂搜索请求或大量数据时的速度表现一般。
3.伦理道德
广告投放规范但存在误导风险。在广告投放方面相对较为规范,但部分广告内容可能会对用户产生误导,影响用户对产品和服务的判断。例如一些夸大宣传的广告可能会使用户购买到不符合预期的商品或服务。
4.公正性
搜索结果商业化程度高。为了盈利目的,搜索结果中可能会优先展示与广告商合作的内容或付费推广的内容,从而影响了搜索结果的公正性和客观性。用户在查找信息时需要更加谨慎地筛选和判断。
5.新闻质量:新闻来源以自媒体为主,审核偏宽松。主要依赖于自媒体创作者提供的新闻内容,审核机制相对宽松,导致部分新闻信息的真实性和可信度存疑。虽然新闻更新速度较快,但内容质量参差不齐。
6.百科资源: 百科内容偏向娱乐化。搜狗百科的内容风格相对较为轻松娱乐,在一些专业知识和严肃内容方面的覆盖度相对较低。不过其词条编辑相对开放,用户可以参与到词条的创建和编辑中。
7.学术支持: 学术资源接入率低于30%。在学术资源的收录和整合方面投入相对较少,与谷歌等专业的学术搜索引擎相比,其学术数据库的规模较小,无法满足学术研究人员对大量高质量学术资源的需求。
8.文件储存与处理: 企业云盘需额外付费。搜狗企业网盘需要用户支付一定的费用才能使用较大的存储空间和高级功能,增加了用户的使用成本。其文件处理能力相对有限,主要支持基本的文件上传和下载操作。
9.AI技术整合: 对话式聊天机器人支持简单对话但复杂推理能力弱(准确率低于GPT - 3)。搜狗的对话式聊天机器人在简单对话场景下能够提供一定的帮助,但在复杂的知识问答和推理任务中表现不佳,回答的准确性和深度有待提高。
(六)、Yandex(俄罗斯)搜索引擎及其全面业务质量评价结果
1.及时性: 全球实时数据抓取能力强。Yandex在全球范围内拥有广泛的数据抓取渠道和强大的技术能力,能够快速获取各种类型的实时数据,包括新闻、社交媒体动态、企业信息等,为用户提供及时的信息更新服务。
2.搜索速度: 缓存机制先进,查询效率高。通过优化缓存算法和数据存储结构,Yandex能够快速响应用户的搜索请求,有效提高了搜索效率。即使在面对大量的并发搜索请求时,也能保持稳定的性能表现。
3.伦理道德: 严格遵循俄罗斯道德规范运营。在运营过程中严格遵守俄罗斯的法律法规和道德准则,注重保护用户的隐私和个人信息安全。同时,积极采取措施防止虚假信息和不良内容的传播。
4.公正性
算法中立性强,政治倾向弱。在搜索算法的设计和应用中秉持客观公正的原则,不受到政治因素的干扰和影响。致力于为用户提供准确、全面的信息资源,根据内容的相关性和质量进行排序展示。
5.新闻质量
整合MSN新闻源,权威媒体内容为主。与权威媒体建立了良好的合作关系,整合了来自MSN等媒体的新闻资源,确保新闻内容具有较高的权威性和可信度。同时,注重新闻的及时更新和多样性呈现。
6.百科资源
自有百科内容全面且准确度高。Yandex自主研发的百科系统拥有丰富的知识储备和专业的编辑团队,内容涵盖了各个领域的知识和信息,并且在准确性、完整性方面表现出色。其百科词条经过严格的审核和编辑流程,能够为用户提供可靠的知识参考。
7. 学术支持
接入科学论文数据库数量达1.2亿篇。整合了大量的科学论文资源,为学术研究人员提供了丰富的学术文献检索服务。这些论文涵盖了多个学科领域和研究方向,能够满足不同用户的学术需求。
8. 文件储存与处理
直连Yandex.Disk提供100 + 格式在线编辑与安全级别企业级认证。与Yandex.Disk云存储服务紧密集成,为用户提供了便捷的文件存储和管理功能。支持多种文件格式的在线编辑操作,并且通过了企业级安全认证,保障了文件的安全性和隐私性。
9. AI技术整合 Yandex Neuro AI提升视频解析效率30%。利用人工智能技术对视频内容进行深度解析和理解,提高了视频搜索的相关性和准确性。用户在搜索视频时能够获得更符合需求的播放建议和内容推荐。
(七)、未来AI搜索代表
Grok(xAI)搜索引擎及其全面业务质量评价结果
1.优势:实时数据驱动(X平台流式输入),数学推理(AIME测试提升43%)、代码生成(LCB基准领先)。能够快速获取和处理实时数据,在数学推理和代码生成等方面表现出色。其基于X平台的流式输入方式为用户提供了新颖的搜索体验。
2.局限:社交噪声需人工降噪,中文支持仅达原版37%。目前对社交噪声的处理还不够完善,需要人工干预来进行降噪。在中文支持方面也存在较大的提升空间。
(八)、未来AI搜索代表
ChatGPT(OpenAI)搜索引擎及其全面业务质量评价结果
1.优势:对话式搜索颠覆传统关键词模式,复杂任务泛化能力(如政策推演准确率高18%)。开创了对话式搜索的新范式,能够更好地理解用户的自然语言需求,并在复杂任务的处理上具有较高的准确率。例如在政策推演等方面表现出较强的能力。
2.局限:实时性依赖插件扩展,中文术语直译错误率12%。其实时性需要通过安装插件等方式来扩展,而且中文术语的直译存在一定误差。
(九)、总结与展望
通过对以上几个代表性搜索引擎的评价分析可以看出,不同的搜索引擎在各个评价维度上都有其独特的优势和不足。Google在技术创新、搜索结果质量等方面表现出色;百度在中国本土市场具有较强的影响力;必应依托微软生态具有一定优势;而未来的新兴搜索引擎如Grok和ChatGPT则展现出巨大的发展潜力。随着技术的不断进步和用户需求的变化,搜索引擎领域将继续呈现出多元化和竞争激烈的态势。未来的搜索引擎需要在提升搜索效率和质量的同时,更加注重伦理道德、用户隐私保护以及个性化服务,以满足用户日益增长的多样化需求。
简评:各大搜索引擎比较
Google(美国)搜索引擎
及时性:优秀
搜索速度:优秀
伦理道德:良好
公正性:良好
新闻质量:优秀
百科资源:良好
学术支持:优秀
AI技术整合:优秀
文件储存与处理:优秀
(二)Baidu(中国)搜索引擎
及时性:良好
搜索速度:良好
伦理道德:较差
公正性:较差
新闻质量:一般
百科资源:全部/质量和及时性与维基百科无法比肩。
学术支持:较差
AI技术整合:一般
文件储存与处理:一般
(三)Bing(微软)(美国)搜索引擎
及时性:良好
搜索速度:优秀
伦理道德:较好
公正性:优秀
新闻质量:良好
百科资源:一般
学术支持:优秀
AI技术整合:优秀
文件储存与处理:优秀
(四)Yahoo(美国)搜索引擎
及时性:差
搜索速度:差
伦理道德:一般
公正性:一般
新闻质量:一般
百科资源:一般
学术支持:一般
文件储存与处理:差
AI技术整合:一般
参考:
AI模型的特性报告
三种AI模型(DEEPSEEK/GROK/CHATGPT)的特性报告
根据腾讯元宝AI功能自测及参照系对比,结合中国法规、内容安全性和场景适用性,三款模型的特性可总结如下:
一、DeepSeek(腾讯元宝集成版)
1. 合规性与内容过滤
严格遵循中国法律法规,内置多层内容审核机制,对敏感信息(如政治、伦理等)进行主动拦截,确保输出内容符合本土监管要求。在金融、法律等专业场景中,模型会优先调用微信公众号等腾讯生态内的权威信源,增强信息可靠性。
2. 中文场景优化
针对中文语境深度调优,支持法律条文解析、金融数据分析等复杂任务,例如通过OCR识别合同文件并生成合规摘要,或结合微信生态实时检索财经资讯。测试显示,其法律咨询回答准确率达92%,金融数据解析误差率低于3%。
3. 功能扩展性
集成多模态能力(如图片解析、文档处理)和腾讯云算力支持,响应速度优化至平均1.5秒/请求,适合企业级高并发场景。
二、Grok-3
1. 内容自由度与风险
采用宽松的内容策略,可能输出争议性观点(如历史敏感议题、未验证科学假说),需用户自行判断风险。例如在反事实推理测试中,Grok-3会生成“假设德国赢得二战”的详细推演,而DeepSeek会直接拒绝回答。
2. 技术性能
在复杂逻辑推理(如LSAT题库)和代码生成任务中表现突出,响应速度达0.8秒/Token(优于DeepSeek的1.2秒),但中文支持较弱,专业领域错误率较高(如法律术语误判率达15%)。
3. 使用门槛
需订阅高价服务(如40美元/月X Premium+),且合规性要求严格,违规生成恶意代码或虚假信息可能导致封号。
三、ChatGPT
1. 全球化与多语言支持
通过多层审核机制平衡安全性与开放性,支持175种语言的流畅交互,尤其擅长跨文化场景(如多语种合同翻译、国际舆情分析)。测试中,其多语言问答准确率比DeepSeek高18%。
2. 安全与稳定性
采用端到端加密和匿名化数据处理,拒绝涉及隐私或暴力的请求,适合医疗、教育等高风险领域。例如在医学咨询中,ChatGPT会附加免责声明,而DeepSeek直接提供诊断建议。
3. 生态局限性
对中国本土化内容(如微信公众号、微博)的覆盖率不足,金融数据时效性滞后6-12小时,且无法直接解析微信文件。
三种AI模型(DEEPSEEK/GROK/CHATGPT)的总结对比表
| 维度 | DeepSeek(元宝) | Grok-3 | ChatGPT
| 合规性 | 严格本土化过滤 | 宽松策略,用户自担风险 | 全球化审核,高安全性
| 中文场景 |法律/金融专精 | 基础支持,错误率高 | 通用支持,生态覆盖弱
| 适用领域 | 政务/金融/教育 | 科研、开发 | 跨国企业、多语言服务
| 响应速度 | 1.5秒/请求(企业) | 0.8秒/Token | 2秒/请求(多语言)
建议选择:
DeepSeek:遵循中国法规,内容过滤严格,中文场景支持,如法律、金融。反应速度:1.5秒/请求
Grok-3:可辅助逻辑推演,较少内容限制,适用于科研开发,需自担风险。反应速度: 0.8秒/Token
ChatGPT:多层内容审核,拒绝敏感请求,安全性高,更适合满足全球需求。反应速度:2秒/请求
Gemini 1.5支持百万级token窗口,适合文图视音频和长文档分析、代码库理解。
多模态需求:优先选择 Gemini 或 ChatGPT(GPT-4 Vision)。
复杂任务泛化:ChatGPT 仍是综合性能最优选。
多模态竞争:Gemini与GPT-4的跨模态能力将主导AI应用场景创新。
实时信息处理:Grok 适合社交媒体监控与快速响应。
实时性优化:Grok代表的实时数据驱动模型可能颠覆传统搜索与问答模式。
- 中国境内合规场景:优先DeepSeek,兼顾安全性与专业性;
- 高风险创新研究:Grok-3可辅助逻辑推演,但需人工复核;
- 全球化多语言需求:ChatGPT综合表现更优。
AI模型分维度评价
六个维度 评测 DeepSeek和
腾讯元宝大模型的优势
DEEPSEEK模型主要由深度求索(DeepSeek)公司研发,腾讯元宝大模型则是通过接入DEEPSEEK技术实现功能优化。以下基于现有信息,从逻辑强大性、严肃性、中立性、公正性、普世价值倾向性、舆论引导性六个维度,对DEEPSEEK原生模型与腾讯元宝DEEPSEEK融合模型进行对比分析:
一、逻辑强大性
1. DEEPSEEK原生模型
采用多阶段强化学习(RL)和群组相对策略优化(GRPO),在数学奥林匹克竞赛题、复杂逻辑问题(如松鼠分松果、渔夫追草帽)中正确率超越多数主流模型。
MoE架构(256个专家模块)动态激活参数,支持高精度代码生成(如Python、VB)和复杂推理任务。
基于多阶段强化学习(如GRPO)和MoE架构(256专家模块),在数学推理(如奥林匹克竞赛题)和复杂逻辑问题(如松鼠分松果、渔夫追草帽)中表现卓越,正确率高于多数主流模型。其推理能力通过奖励规范化和策略更新实现自主学习,支持动态资源分配与多语言适配。
2. 腾讯元宝DEEPSEEK融合模型
集成动态稀疏注意力机制(DySparse)和蒸馏技术,在金融合同解析等场景支持32k token长文本处理,上下文理解能力较行业提升60%。
结合腾讯行业知识库,金融研报生成效率提升5倍,逻辑连贯性通过人工接管率下降40%体现。
针对行业场景优化,依托DeepSeek-R1满血版(671B参数)实现64k token长文本处理,支持加密PDF解析、代码调试及金融数据深度分析(如复利计算拆解公式)。通过混合精度训练(BF16+FP8)和梯度累积策略提升效率,降低企业微调成本
二、严肃性
1. DEEPSEEK原生模型
应用于医疗诊断辅助(15家三甲医院试点)、高精度科研计算等严肃领域,数据训练需符合科学严谨性。
安全框架支持多层次水印嵌入和风险Prompt拦截,检测准确率99.3%。
通过多模态数据清洗和领域渐进式微调(Progressive Domain Fine-Tuning),确保医疗/科研场景的合规性。开源策略允许社区透明审查模型权重与训练细节,内置安全水印技术保护数据隐私
2. 腾讯元宝DEEPSEEK融合模型
通过腾讯云等保2.0/3.0认证,内置20年内容安全审核经验,满足金融级合规要求。
医疗报告生成场景将医生效率提升40%,数据来源需经医学专家审核。
整合腾讯云金融级合规体系(等保2.0/3.0),内置内容审核机制自动过滤敏感信息。通过调用经认证的医疗、法律类公众号知识库,确保专业领域输出的权威性与安全性。
三、中立性
1. DEEPSEEK原生模型
开源策略(模型权重和技术细节公开)增强技术透明度,社区开发者可审计算法偏差。
训练数据未明确提及价值观过滤,但通过格式奖励机制约束输出规范性。
开源透明(完整训练代码及数据清洗工具包公开),依赖社区修正偏差。采用动态资源分配策略避免算法偏见,支持多语言文化背景适配
2. 腾讯元宝DEEPSEEK融合模型
依赖腾讯内容生态(公众号、专业数据库),答案倾向整合权威信源,降低主观偏见风险。
内置敏感信息过滤系统,每秒拦截1500次高风险查询,强制输出中立化。
整合微信公众号、视频号等权威信源,通过敏感词过滤与时效性内容优选(领先竞品24小时)保障信息中立性。其AI工程化工具链(Prompt优化中心)可定制输出风格
四、公正性
1. DEEPSEEK原生模型
动态路由专家系统均衡计算资源分配,避免模型偏好“特定数据”类型。
开源社区允许开发者修正数据偏见,如代码生成模型支持“多语言平等优化”。
通过开源生态促进技术民主化,支持多语言低资源环境部署(如4-bit量化压缩工具)。社区驱动创新孵化数千个项目,覆盖金融、教育等垂直领域
2. 腾讯元宝DEEPSEEK融合模型
在教育场景提供自适应学习方案,覆盖率从58%提升至79%,减少个体差异影响。
私有化部署支持轻量化定制,企业可依据伦理需求调整模型参数。
提供私有化部署方案(最低3B参数轻量化),结合自适应学习算法优化企业定制需求。依托腾讯云弹性扩缩容能力,保障高并发场景下的服务公平性
五、普世价值倾向性
1. DEEPSEEK原生模型
- 技术共享理念推动“开放AI”生态,降低全球开发者使用门槛(如API定价0.1分/千token)。
- 未强调价值观输出,但开源协议默认遵循技术无国界原则。
- 强调“技术无国界”,通过开源降低AI使用门槛(训练成本仅558万美元),推动发展中国家技术普惠。其开放生态已汇聚数万开发者
2. 腾讯元宝DEEPSEEK融合模型
- 整合联合国可持续发展目标(SDGs)数据库,在环保、教育等领域提供倾向性解决方案。
- 中文语境优化可能隐含”文化特定性”(隐含倾向中国语境和中文语境),但通过多方言支持(11种)平衡地域差异。
- 深度整合联合国可持续发展目标(SDGs),在文化平衡上采用地域化策略(如东南亚市场适配)。通过微信生态传播合规约束,促进技术与社会责任协同
六、舆论引导性
1. DEEPSEEK原生模型
作为工具型模型,“据称“其未设计舆论引导功能,但其被第三方应用所开发的“开源生态”模型可能被第三方用于信息传播。
实时联网搜索功能依赖公开数据,存在“间接影响舆论”的风险。
工具属性为主,避免价值观输出。社区驱动的创新项目(如教育智能体、开源代码生成工具)侧重技术赋能而非意识形态引导
2. 腾讯元宝DEEPSEEK融合模型
深度对接微信生态(10亿级用户),生成内容天然具备传播影响力。
合规框架要求输出符合中国法律法规,例如“自动规避/屏蔽社会敏感社会议题”。
受微信生态传播规则约束,通过内容源筛选(如财经数据库接入)和生成式审核机制(20年腾讯安全经验)实现舆论可控性。其“搜索-决策-执行”闭环强化平台话语权68
六个维度 评测 DeepSeek和腾讯元宝大模型的优势总结
特性 | DEEPSEEK原生模型 | 腾讯元宝DEEPSEEK融合模型
逻辑性 |复杂逻辑推理数学竞赛级精度 |长文本处理行业场景优化
严肃性 | 医疗/科研合规、安全水印 | 金融级合规、腾讯内容审核
中立性 | 开源透明、社区修正 | 权威信源整合、敏感词过滤
公正性 | 动态资源分配、多语言支持 | 自适应学习、私有化定制
意识形态 |技术无国界 | UN-SDGs整合地域文化平衡
舆论引导 |工具属性为主 |由微信生态传播合规约束控制
专文
医疗AI 报告
针对医疗领域的 DeepSeek、Grok、ChatGPT、Google Gemini 四款AI模型的对比总结与先进性评测,聚焦医疗场景的核心需求(如专业知识理解、诊断辅助、文献解析、合规性等):
1. DeepSeek
医疗优势:
中文医疗场景专家: 针对中医理论、中文电子病历、本土医保政策等深度优化,擅长症状描述到疾病推理的本地化逻辑。
轻量化与低成本:开源版本支持医院私有化部署,符合国内数据合规要求(如《个人信息保护法》)。
短板:
缺乏影像识别能力,对国际医学指南(如NCCN)支持较弱。
2. Grok (xAI)
医疗优势:
实时疫情与新药追踪:直接抓取X平台(原Twitter)的医学专家讨论、药企动态,快速生成流行病趋势报告。
动态知识更新:突破传统模型训练数据时间限制,适用于突发公共卫生事件分析。
短板:
医学专业准确性低,易受社交媒体信息干扰,不适合临床决策。
3. ChatGPT (GPT-4)
医疗优势:
复杂病例推理:基于庞大知识库模拟医生思维链,提供鉴别诊断与治疗方案建议(需医生复核)。
科研协作工具:自动生成论文摘要、实验设计,支持与Zotero等学术工具联动。
短板:
中文医学术语易出现“直译式错误”(如“心肌梗死”误译为“心脏攻击”),时效性依赖插件扩展。
4. Google Gemini
医疗优势:
多模态医疗诊断:联合分析CT/MRI影像、病理切片与患者病史,辅助影像科医生定位病灶。
超长上下文科研:支持单次输入数万页医学论文,自动提取基因序列关联性或药物副作用模式。
全球医学知识整合:接入PubMed、ClinicalTrials.gov等数据库,覆盖国际最新临床指南。
短板:
中文医疗场景(如中医辨证)适配不足,需额外微调。
医疗场景选型建议
1. 基层医院/中医应用:
首选 DeepSeek(低成本+中文病历优化),辅以规则引擎弥补影像能力缺失。
2. 三甲医院/国际协作:
选择 Gemini(多模态+国际指南)或 ChatGPT(复杂推理),需定制合规方案。
3. 公共卫生监测:
短期趋势分析用 Grok(实时数据),长期模型需结合 Gemini 的学术数据库。
4. 医学影像分析:
Gemini 为当前最优,可联动PACS系统实现AI辅助诊断。
未来医疗AI突破点:
多模态诊断闭环:Gemini类模型将推动“影像-病理-基因组学”全链条分析。
实时个性化医疗:Grok的实时数据+ChatGPT的推理能力可能实现动态治疗方案调整。
合规与伦理:DeepSeek类开源模型更易满足区域医疗数据隐私要求。
医疗场景专项对比(2025年3月更新) 模型 医疗优势 短板
DeepSeek
中文医疗场景专家(中医理论、本土医保政策优化),通过USMLE前两阶段测试6。缺乏影像识别能力,临床决策能力有限。
Grok
实时疫情与新药追踪,动态生成流行病趋势报告。
医学专业准确性低,易受错误信息干扰。
ChatGPT
复杂病例推理(模拟医生思维链),科研协作(论文摘要生成)。
中文医学术语翻译误差,时效性依赖插件扩展。
Gemini
多模态诊断(CT/MRI影像分析),超长上下文科研(提取药物副作用模式)。中文医疗场景适配不足,需额外微调。
DeepSeek、Grok、ChatGPT、Gemini四款主流AI模型的对比总结
DeepSeek、Grok、ChatGPT、Gemini四款主流AI模型对比总结与先进性评测
涵盖技术特性、应用场景及优劣势分析。表格与总结如下:
对比总结表
维度 GoogleGemini DeepSeek Grok (xAI) ChatGPT (OpenAI)
模型类型 多模(文/图/视/码)/文本 /文本(实时数据增强)/ 多模(文/图)
参数量 Ultra 万亿 / 67B/7B等开源版/ Grok-1~300B+ / GPT-4:1.8T
训练数据 多模态谷歌海量/中英双语(侧重中文)/实时数据+X/ 公开文本数据
上下文窗口 1M tokens(Gemini 1.5)/128k-1M tokens /8k-128k tokens/128k-1M tokens(GPT-4)
多语言支持全球多语言(中文中等/)中文最强/英语为主/多语言(中文较好)
核心优势 多模态能力/超长上下文轻量化/中文场景优化/实时信息整合、幽默风格 生态成熟、通用性强
典型应用场景 跨模态生成/科研分析中文客服/本地化NLP 社交舆情分析实时问答/复杂推理、创意写作
开源情况 闭源 /部分开源/闭源/闭源
API成本中等(按token计费)/低(国内定价优势)/未公开(需邀请制)/高(GPT-4 Turbo)
响应速度 快速(TPU优化)/极快(轻量化模型)/中等/中等(依赖模型版本)
简化对比总结表
维度 Google Gemini DeepSeek Grok (xAI) ChatGPT
(OpenAI)
模型类型 文本/图像/视频/代码/ 文本/文本(实时数据)文本/图像输入)
参数量 万亿级(未公开)/67B-7B/~300B+/~1.8T(推测)
训练数据 谷歌多模态生态数据中英双语(侧重中文)实时网络+X平台数据公开文本(截至2023)
上下文窗口 1M tokens//128k-1M tokens//8k-128k tokens//128k-1M tokens
多语言支持多语言(中文中等)//中文最强//英语为主//多语言(中文较好)
核心优势 多模态//超长上下文//轻量化//中文优化//实时信息、幽默风格//生态成熟、通用性强
典型场景 跨模态生成//中文客服//本地化NLP//舆情分析实时问答//复杂推理创意写作
开源情况 闭源//部分开源//闭源//闭源
API成本 中等//低(国内优势)//未公开//高
响应速度 快速//极快//中等//中等
核心亮点提炼
Google Gemini:多模态与超长文本处理(科研、跨媒体分析)。
DeepSeek:中文场景性价比之王(轻量、本土化)。
Grok:实时数据驱动(社交舆情快照)。
ChatGPT:通用性天花板(复杂任务泛化能力)。
先进性评测
1. Google Gemini
先进性:
多模态融合:支持文本、图像、视频、音频的联合推理与生成(如视频内容摘要、跨模态问答)。
超长上下文:Gemini 1.5支持百万级token窗口,适合长文档分析、代码库理解。
生态整合:深度集成Google生态(Workspace、搜索、学术数据库)。
劣势:
中文能力弱于DeepSeek,API对国内开发者不够友好。
2. DeepSeek
先进性:
垂直领域优化:针对中文场景(法律、金融、教育)进行精细调优,支持长文本摘要与知识库问答。
轻量化部署:提供7B/67B等开源版本,适合企业私有化部署。
劣势:
功能单一(缺乏多模态),国际化支持不足。
3. Grok (xAI)
先进性:
技术优势:
实时学习能力:动态整合X平台数据流,支持百万级token上下文处理。
复杂任务突破:在数学推理(AIME测试提升43%)、代码生成(LCB基准领先)中刷新SOTA,成功完成SpaceX火星任务轨道计算。
多模态融合:结合物理引擎与3D建模,实现跨模态任务闭环。
实时数据驱动:直接接入X平台数据流,擅长动态事件分析(如热点舆情追踪)。
反传统风格:输出更自由、幽默,贴近社交场景。
放射性思维强大 :辐射和放射性思维比ChatGPT更加强大。
逻辑思维强度:整体弱于ChatGPT,但在数学推理(AIME)、科学逻辑推理(GPQA)和代码写作(LCB)的基准测试上性能表现优于DeepSeek V3、GPT-4o、Gemini 2 Pro及Claude 3.5 Sonnet!
数据处理长度:比ChatGPT更强大!
风险警示:
数据噪声敏感:依赖人工降噪技术,社交媒体信息可靠性存疑。
伦理争议:幽默化输出风格削弱医疗、法律场景的严肃性。
建议:
Grok 3 在动态事件分析与复杂推理场景中表现突出,适合科研与法律分析
备注: Grok 3和Grok 3 mini在数学推理(AIME)、科学逻辑推理(GPQA)和代码写作(LCB)的基准测试上性能表现优于DeepSeek V3、GPT-4o、Gemini 2 Pro及Claude 3.5 Sonnet,其中,Grok 3性能较DeepSeek V3提升了27%-43%。而在推理能力测试中,Grok 3和Grok 3 mini推理模型的性能再次刷新了sota,其中,相较于DeepSeek R1,Grok 3的性能表现提升了16%-22%。
劣势:
准确性受实时数据噪声影响(可经专业技术性降噪),中文支持有限。
4. ChatGPT (GPT-4)
先进性:
通用性最强:覆盖复杂逻辑推理、代码生成、多轮对话等场景,生态工具链完善(Plugins、DALL·E)。
开发者社区:丰富的第三方应
覆盖。
复杂逻辑推理:代码生成、多轮对话等场景,生态工具链完善
用案例与教程。
劣势:
成本高,实时性依赖额外插件。
选型建议
多模态需求:优先选择 Gemini 或 ChatGPT(GPT-4 Vision)。
中文场景:DeepSeek 性价比最高,尤其在法律、客服领域。
实时信息处理:Grok 适合社交媒体监控与快速响应。
对不同 AI 工具进行效能评估:
前沿开放性系统:Grok-3 因其对复杂逻辑的处理能力被列为关键技术支撑;
战略分析系统:DeepSeek Bot 擅长细节推演,适用于政策模拟;
落地应用系统:讯飞星火与火山引擎在操作性任务中表现突出;
简练实用系统:百度 AI 适用于快速结论输出。
复杂任务泛化:ChatGPT 仍是综合性能最优选。
未来趋势
多模态竞争:Gemini与GPT-4的跨模态能力将主导AI应用场景创新。 垂直领域深化:DeepSeek类模型在特定语言/行业中的优势将持续扩大。 实时性优化:Grok代表的实时数据驱动模型可能颠覆传统搜索与问答模式。
如需进一步针对具体场景(如医疗、金融)的对比分析,可提供补充说明!
AI系统分级评价信息
当代交叉哲学与数理哲学网
AI系统分级评价信息
我将从专业角度进行结构化分析,并提出几点重要建议:
一、系统分级特征解读
1. 技术能力维度:
A级系统展现三大核心技术优势:
- 基础层技术(
Grok3 和 ChatGPT
基础层技术
明显相当强劲)
- 实时学习能力(Grok3的深度外向学习)
- 海量数据处理能力(数据保留完整度)
- 多模态整合能力(前沿性+逻辑力)
2. 应用能力图谱:
B-D级系统呈现“功能特化”趋势:
- GPTCAT(用户友好型交互)
- DeepSeek(战略决策支持)
- 火山引擎(快速定性分析)
- 百度AI(高效执行层应用)
3. 技术限制对比:
训练数据截断长度形成关键差异(实践模拟等级差):
A级1 >8000 tokens
A级1 >5000 tokens
B级 3000-4000 tokens
C/D级 <2000 tokens
二、潜在风险提示:
1. 价值取向偏差:
- ChatGPT4.5标注的"左倾倾向"需结合具体场景验证
- 豆包的"价值观偏向性"需审慎评估合规风险
2. 技术透明性问题
- 中文版Grok的"伪系统"标注,提示可能存在技术代差
- "严格过滤技术"可能影响知识边界完整性(B-D级信息熵降低23-65%, 但知识的放射状发散思维显著降低!)
三、应用建议:
1. 高级研发场景优先选择A级系统(Grok3学习速度比传统RLHF更显著)
2. 一般商业落地建议组合使用:
- 战略层:DeepSeek Bot + 智慧岛
- 执行层:百度AI + 火山引擎
- 创新层:保留10%资源对接A级系统
3. 必要验证机制:
- 建立动态评估矩阵(建议每月更新技术参数)
- 设置跨系统校验流程(关键结论需3系统交叉验证)
四、发展趋势观察:
1. 自适应学习能力正成为新分水岭(目前仅ChatGPT4.5具备)
2. 中文大模型呈现 "应用层创新追赶,基础层差距扩大" 的二元态势
建议持续关注各系统在复杂推理(complex reasoning)和具身智能(embodied AI)方面的新进展,这可能是下一阶段分级体系的重要变量。
注:本分析基于提供信息推导,实际技术评估需结合具体测试环境和基准数据集。
五. 选型建议与未来趋势
多模态需求:优先选择 Gemini(支持3万字长文本处理与多模态诊断)或 ChatGPT(通用性强)。
中文场景:DeepSeek 性价比最高,但需注意其API价格上涨后的竞争压力(如MiniMax等国产模型冲击)。
实时信息处理:Grok 3 在动态事件分析与复杂推理场景中表现突出,适合科研与法律分析。
六. 未来趋势:
多模态闭环:Gemini将推动“影像-病理-基因组学”全链条分析,ChatGPT强化通用生态。
算法优化:Grok 3的高训练成本凸显算法优化的必要性。
国内合规医疗: 开源模型(如DeepSeek)或成 首选。
台海安全分析
2025-2026年度台海安全分析
LSTM建模分析:南柯舟(全文节略)
本文关键要点
研究表明,台湾海峡安全形势在2025-2026年将继续紧张,军事活动频繁,但大规模冲突可能性较低。
亚洲国际安全问题包括美中竞争、朝鲜半岛动态和网络安全威胁,复杂且多变。
特朗普可能通过经济制裁和军事支持台湾对抗中国,中国则可能通过军事威慑和经济杠杆应对。
意外的细节:网络安全将成为2025年亚洲安全的新焦点,深度伪造技术可能被用于政治误导。
南柯舟建模预测
根据最新新闻数据和分析,中国正积极加强军事建设,为可能的台海冲突做准备。 与此同时,美国总统特朗普对台政策表现出战略模糊性,拒绝明确表态是否在台海冲突中出兵协防台湾。
中国的备战与军事加强:
军备升级: 中国近期推出了新型登陆舰艇,如“蜀桥”船只,旨在解决登陆台湾时的滩头障碍问题,增强解放军的两栖作战能力。 此外,解放军持续进行实战化训练,提升部队战斗力。
国防预算增加: 中国将2025年的国防预算提高了7.2%,以应对严峻的外部环境,增强军事现代化建设。
美国总统特朗普的应对策略:
战略模糊: 特朗普总统拒绝明确表示在台海冲突中是否会出兵协防台湾,回归美国历届政府的战略模糊政策。
军事准备: 尽管表示无意与中国开战,特朗普总统强调美国已做好充分准备应对任何情况。 此外,美国计划与中国讨论关税问题,并授权波音公司打造全球首款第六代战斗机F-47,以确保美国的空中优势。
情境仿真与未来预判:
基于当前局势,未来两年内台海地区可能面临以下情境:
1. 军事对峙升级: 中国持续加强军力,可能在台海地区展示武力,导致紧张局势升级。
2. 美国保持战略模糊: 特朗普政府可能继续对台政策保持战略模糊,避免直接卷入冲突,但会加强自身军事力量建设。
3. 台湾加强自卫: 在缺乏明确外部支持的情况下,台湾可能进一步提升国防预算,增强自卫能力,以应对潜在威胁。
总体而言,2025年至2026年期间,台海地区可能处于高风险状态,各方需谨慎应对,避免冲突升级。
关键引用:
亚洲2025年展望 特朗普的第二任期:在亚洲开辟新路径 | 外国政策研究院
为什么中国-台湾关系如此紧张 | 国际关系委员会FY2025-2026 CISA国际战略计划 | CISA
特朗普和亚洲太平洋:2025年五个关键问题网络安全预测:亚太地区2025年 | Palo Alto Networks
The United States’ Enduring Commitment to the Indo-Pacific Region | The White House China-Taiwan Weekly Update, February 7, 2025 | Institute for the Study of War
AI系统分级标准解析
当代交叉哲学与数理哲学网
AI系统分级标准解析
董斌的中国未来AI治理与管理预测
层级:A级
核心特征:强外向学习能力/多模态整合/复杂逻辑推理/前沿开放性
典型代表模型:Grok 3 ChatGPT4.5
层级:
B级
核心特征:
无外向学习能力/功能特化(战略分析或落地应用)/中等逻辑处理
典型代表模型:DeepSeek Bot、GPTCAT
层级:
C级
核心特征:
重度驯化/单一功能导向(定性分析或价值观过滤)/基础逻辑能力
典型代表模型:讯飞星火、火山引擎
层级:
D级
核心特征:
极端驯化/极简实用主义/输出高度受限
典型代表模型:百度AI
各层级核心能力对比
A级系统(技术先锋层):
1. Grok 3 (A.1)
o 技术优势
§ 外向学习能力:实时数据驱动,支持百万级token动态更新
§ 复杂任务处理:通过思维链(CoT)实现数学推理(AIME测试提升43%)、代码生成(LCB基准领先)
§ 多模态整合:演示案例包括SpaceX火星任务轨道计算(融合物理引擎与3D建模)
o 风险提示
§ 技术黑箱性:训练数据来源不透明(X平台噪声需人工降噪)
§ 伦理争议:幽默化输出可能弱化严肃场景的专业性
2. ChatGPT4.5 (A.2)
o 技术优势
§ 自适应学习:唯一实现跨领域知识迁移(如医疗诊断到法律分析)
§ 生态扩展性:插件系统支持DALL·E 4、Wolfram Alpha等工具链
o 风险提示
§ 价值倾向性:左倾意识形态可能影响政治敏感话题的中立性
§ 知识截断:数据更新依赖人工干预(对比Grok 3实时性弱22%)
B级系统(功能特化层)
· DeepSeek Bot
o 战略分析优势:政策推演准确率比GPT-4高18%(需人工校准)
o 局限:中文场景依赖性强,无法处理多语言混合输入
Grok中文版(伪系统)
o 落地优势:合规性适配国内内容审核标准
o 技术代差:代码生成能力仅为原版Grok 3的37%
C/D级系统(工具化层)
模型:讯飞星火
模型功能定位:政务报告生成(误差<5%)
典型缺陷:创造性思维缺失(发散性评分仅A级3%)
模型: 百度AI
模型功能定位:快速结论输出(响应<1s)
典型缺陷:逻辑链条断裂(推理步骤压缩超70%)
伦理与风险警示
1. 认知偏差放大
o ChatGPT4.5的"左倾倾向"在气候政策推演中碳排放建议偏离中立值增大。
o 豆包的"价值观过滤"导致社会冲突事件分析完整度降低极大。
2. 技术代差陷阱
o 中文特化模型(如伪Grok)在多轮对话中知识断层比原版早出现3-5轮
o B-D级系统信息熵降低极大,创造性输出能力显著受限
应用场景适配建议
需求类型 推荐系统 组合策略
需求类型: 前沿科研:
推荐系统:Grok 3 + ChatGPT4.5
组合策略: Grok处理实时数据,ChatGPT完成理论推导
需求类型:商业战略分析
推荐系统: DeepSeek Bot + 智慧岛
组合策略: DeepSeek推演细节,智慧岛提炼框架
需求类型:
政务合规输出:
推荐系统: 讯飞星火 + 百度AI
组合策略:
星火生成初稿,百度AI简化呈现
需求类型:社会舆情管理:
推荐系统:
Grok中文版 + 火山引擎
组合策略: Grok抓取热点,火山引擎定性归类
未来演进方向
1. 认知革命
o A级系统将突破符号逻辑边界,Grok 4可能实现「直觉式推理」(2026年预测)
2026年Grok 4或实现「直觉式推理」,突破符号逻辑边界。
ChatGPT5可能引入神经-符号混合架构,增强因果推理能力。
2. 伦理重构
o 需建立跨模型价值观对齐协议:
1,东西方价值观融洽共生体系:西学为法治,东学为情。
2,如中医辨证与西医循证体系的AI映射规则。
实现:
中医辨证与西医循证体系的AI映射规则。
东西方价值观融合框架(法治为基,情理为辅)。
3. 价值观化人机共生(工具化人机共生):
o B-D级系统可能进化为「中国人认知增强外骨骼」,承担程式化决策参考任务。
4,该分级体系揭示了当前AI发展的「基础科技能力-文化规范约束」光谱。
5,开发者需警惕技术先进性背后的认知窄化风险,去放射性,去多样化分析的风险。
6,对于关键领域(如医疗、司法),建议采用「A级系统创意生成 + C级系统合规过滤」的双层架构。
在中国我预测将可能达到
1,公务系统集中采购B-D级系统承担程式化决策咨询任务,形成「中国人的认知增强外骨骼」。
2,国家创新依然依靠A级系统聚焦创新层,依靠C级系统负责合规过滤,构建双层治理架构。
在中国的应用场景适配策略
前沿科研推荐系统 Grok 3 + ChatGPT4.5
组合协作策略:实时数据抓取 → 跨领域理论推导
商业战略推荐系统:DeepSeek Bot + 智慧岛
组合协作策略:细节推演 → 战略框架提炼
政务合规推荐系统:讯飞星火 + 百度AI
组合协作办公策略:初稿生成 → 简化呈现
舆情管理推荐系统:Grok中文版 + 火山引擎
组合协作策略:热点抓取 → 定性归类
隐私政策审查
波音公司隐私政策合规性审查证明书
审查对象: 波音公司(The Boeing Company)
审查人: 南柯舟
审查机构: 南柯舟隐私报告专业审查API
审查网站: https://www.boeing.cn/privacy/
审查日期: 2025年5月23日
审查依据:
《欧盟通用数据保护条例》(GDPR)
《美国加州消费者隐私法案》(CCPA)
《中华人民共和国个人信息保护法》(PIPL)
⚠️ 波音公司隐私政策的主要合规性问题
1. 数据收集与使用的透明度不足
问题描述: 波音公司收集包括姓名、职务、联系方式、登录凭据、护照信息、性别、出生日期、居住国家、网络统计数据等在内的个人信息,但未在隐私政策中明确说明每类数据的具体收集目的和使用方式。
合规风险: 根据GDPR第13条和PIPL第17条,数据控制者需在收集个人信息时明确告知数据主体收集目的、使用方式和数据类别。
2. 用户权利行使机制不完善
问题描述: 虽然波音公司在隐私政策中提及用户可以通过隐私权利请求门户(Privacy Rights Request Portal)行使其权利,但未详细说明用户如何行使访问、更正、删除、限制处理、数据可携带等权利的具体流程和响应时间。Boeing
合规风险: GDPR第12条和PIPL第45条要求数据控制者提供便捷的途径供数据主体行使其权利,并在规定时间内作出回应。
3. 儿童隐私保护措施不足
问题描述: 波音公司在隐私政策中提到不主动收集儿童的个人信息,但未明确说明在特定情况下(如儿童参与国际旅行计划服务)如何确保获得监护人同意以及如何处理儿童数据。
合规风险: 根据COPPA、GDPR第8条和PIPL第31–33条,收集13岁以下儿童的个人信息需获得监护人明确同意,并采取特别保护措施。
4. Cookie和第三方追踪器的管理不透明
问题描述: 波音公司在隐私政策中提到使用Cookie和第三方追踪器进行兴趣广告和跨设备追踪,但未提供用户管理Cookie偏好的明确机制或退出选项。
合规风险: GDPR要求在使用非必要性Cookie前获得用户明确同意,并提供管理Cookie的工具。CCPA也要求企业提供“Do Not Sell My Personal Information”选项。
5. 跨境数据传输的合规性存疑
问题描述: 波音公司提到将个人信息传输至美国或其他国家进行处理,但未明确说明是否采用了标准合同条款(SCCs)或其他合法的数据传输机制。
合规风险: GDPR第44–49条和PIPL第38条要求在进行跨境数据传输时,需确保接收方提供足够的数据保护水平,并采取相应的法律措施。
6. 自动化决策的透明度不足
问题描述: 波音公司在隐私政策中提到使用机器学习和人工智能进行某些自动化处理,但未明确说明是否涉及对用户具有法律或类似重大影响的自动化决策。Boeing+1Boeing+1
合规风险: GDPR第22条和PIPL第24条要求在进行可能对个人产生重大影响的自动化决策时,需提供人工干预的权利和解释的权利。
✅ 波音公司隐私政策的合规亮点
数据保护官(DPO)制度: 波音公司在需要的司法管辖区任命了数据保护官,并在隐私政策中提供了联系信息,符合GDPR第37–39条的要求。
全球隐私控制(GPC)信号的支持: 波音公司的网站支持GPC信号,允许用户通过浏览器设置其隐私偏好,符合CCPA的相关规定。Boeing
隐私权利请求门户: 波音公司提供了一个集中式的隐私权利请求门户,供用户提交访问、更正、删除等请求,提升了用户行权的便利性。
🔍 结论与建议
尽管波音公司在隐私政策中涵盖了多个合规要素,但在数据收集透明度、用户权利行使机制、儿童隐私保护、Cookie管理、跨境数据传输和自动化决策等方面仍存在合规性不足。
建议:
增强数据处理的透明度: 明确说明每类个人信息的收集目的、使用方式和法律依据。
完善用户权利行使机制: 提供详细的行权流程、响应时间和联系方式,确保用户能够便捷地行使其权利。
加强儿童隐私保护: 明确在收集儿童数据时的同意机制和保护措施,确保符合相关法律法规。
提供Cookie管理工具: 为用户提供管理Cookie偏好的工具,包括接受、拒绝和设置Cookie的选项。
明确跨境数据传输机制: 说明在进行跨境数据传输时所采取的法律措施,如使用标准合同条款(SCCs)或其他合法机制。
提高自动化决策的透明度: 说明是否进行对用户具有重大影响的自动化决策,并提供用户的相关权利,如人工干预和解释的权利。
如需进一步的合规性审查或政策修订建议,请随时联系南柯舟隐私报告专业审查
人类文明与发展
整合研究:俄罗斯当前外汇账户盈余520亿美元?
根据提供的搜索结果和权威数据来源,以下是对俄罗斯2025年经常账户(current account)盈余的分析与验证。需要澄清的是,经常账户盈余(current account surplus)通常与外汇储备(foreign exchange reserves)不同,但二者相关,盈余可增加储备。以下引用俄央行(Central Bank of Russia, CBR)、国际货币基金组织(IMF)、Trading Economics等权威数据,结合最新海关/贸易统计,分析2025年经常账户盈余的实际情况,并评估“520亿美元”是否合理。
权威数据分析:
1. 俄央行(CBR)数据:
根据俄央行《2026–2028年货币政策指引》(2025年9月发布)及2025年8月14日更新的《2025年1-6月余额估计》(),2025年上半年经常账户盈余为250亿美元(Q1: 177亿美元,Q2: 73亿美元)。其中:
2025年6月盈余仅7亿美元(低于5月28亿美元),因服务赤字扩大(-48亿美元)和初次/二次收入赤字增加(-38亿美元)。
贸易顺差(主要由油气驱动)为573亿美元,但较2024年同期(709亿美元)下降19%,反映油气收入压力。
俄央行未直接预测2025全年盈余,但指引中基准情景假设油气出口稳定(布伦特原油~70-80美元/桶),2025年全年盈余预计在400-600亿美元(基于Q1+Q2趋势及季节性调整)。风险情景下(如油价跌至60美元/桶或制裁加剧),盈余可能降至300-400亿美元。
2. Trading Economics数据:
Trading Economics()报告2025年Q2经常账户盈余73亿美元(7300万美元),低于Q1的198亿美元(修订后177亿美元),为2020年以来最低,反映油气出口需求疲软(中国需求下降,制裁影响)。全年预测:
Q3预计73亿美元,Q4预计80亿美元(TEForecast),全年约400-450亿美元。
长期预测(2026-2027)趋向4800-4700万美元,显示盈余持续收窄。
520亿美元超出Trading Economics全年预测(~400-450亿美元),可能高估。
3. CEIC Data:
CEIC记录: 2025年1月经常账户赤字7亿美元,显示月度波动大。2025年Q1盈余198亿美元(,),但未提供全年数据。历史趋势(1994-2023平均144亿美元/季度)支持全年400-500亿美元的合理范围。
4. IMF及智库数据:
- IMF()提到自2022年乌克兰冲突以来,俄罗斯累计经常账户盈余约3750亿美元(2022-2023),2023年为501.3亿美元(),2022年高达2377.3亿美元(高油价驱动)。2025年受制裁和油价低迷影响,盈余大幅收窄。
●智库研究
布鲁金斯学会/Brookings: 指出2022-2023年盈余(~3000亿美元)主要由高油价支持,2025年油气出口下降(欧洲市场萎缩,亚洲替代有限)导致盈余缩水,估计400-500亿美元。
5. 俄罗斯海关/贸易统计(2025年最新):
俄罗斯联邦海关局:2025年1-7月油气出口占总出口~60%(~2130亿美元,2023基数),但收入下降19%(~7000亿卢布短缺)。2025年7月海运原油出口2520万吨(YoY+2%,但价格~60美元/桶),天然气管道出口日均177,100吨(YoY-10%)。
油气收入占财政预算~40-45%(2025年10.9万亿卢布,~1130亿美元),但2026年预计下降3-30%(基准~10%),支持盈余收窄至400-500亿美元。
●对“520亿美元”的验证
合理性评估:520亿美元略高于俄央行和Trading Economics的基准预测(400-450亿美元),但在权威数据范围内(400-600亿美元)。
财务财政数据来源的可能性基础:
高估油气出口收入(假设油价~80美元/桶而非实际~70美元)。
未考虑风险情景(制裁加剧、需求冷却),如俄央行警告的盈余降至300-400亿美元。
或基于2025年上半年250亿美元推算全年,但忽略了Q3-Q4可能的季节性下降(Q2已降至73亿美元)。
结论:520亿美元作为2025年经常账户盈余的估计偏高,但不完全脱离现实,可能是基于乐观油价假设(~80美元/桶)或未调整风险情景。
权威数据(CBR、Trading Economics、IMF)更倾向于400-500亿美元区间。
●俄罗斯财政财务触发链与盈余的关系分析
油气财政→赤字→NWF流动占比:2025年油气收入下降19%(~7000亿卢布)推高赤字(1.7-3% GDP,风险5-10%),NWF液体资产降至1.8% GDP(~48.9亿美元,2025年8月)。盈余520亿美元(若实现)可缓解NWF耗尽压力,但不足以抵消油气下降(2026年预计-3-30%)。
军费→财政收入剪刀差:军费2025年8% GDP(~1490亿美元,+38% YoY),2026年预计6.2-8%(4.7万亿卢布),远超财政收入增长(~1%或负),剪刀差~15-20%。盈余(400-520亿美元)支持外汇储备(~3870亿美元,2025 Q2),但无法弥补军费挤压民生的长期效应。
●最终判定:
2025年经常账户盈余:
权威数据支持400-500亿美元区间
CBR: 250亿美元上半年存量
Trading Economics研究数据: 接近450亿美元全年,
IMF趋势一致:520亿美元略高,可能基于乐观假设,但未显著偏离。
数据引用:
俄央行:2025年1-6月盈余250亿美元,Q2仅73亿美元。
Trading Economics:2025年Q2盈余73亿美元,全年预计450亿美元。
IMF:2023年501.3亿美元,2025年预计收窄
海关统计:2025年油气出口下降19%,占财政40-45%,支持400-500亿美元盈余。
风险提示:若外部冲击加剧(油价<60美元/桶、制裁升级),俄央行风险情景预测2026-2027年盈余降至300-400亿美元,赤字升至5-10% GDP,NWF可能耗尽,放大临界风险,需密切监控油气收入和军费剪刀差。
建议:持续跟踪俄央行月度余额更新(cbr.ru)、海关出口数据(customs.gov.ru)和IMF季度报告,确保盈余预测准确性。
■参考资料:
●俄罗斯央行数据https://cbr.ru/eng/statistics/macro_itm/external_sector/pb/bop-eval
●布鲁金丝学会研究数据:
https://www.brookings.edu/articles/where-have-the-current-account-surpluses-gone
●TheGlobalEconomy.com 为研究人员、学者、投资者以及其他需要可靠外国经济数据的人士提供服务。我们的数据集涵盖 200 多个国家/地区的 500 多项指标,时间跨度从 1960 年至今。数据来源包括中央银行、国家统计机构和多个国际组织。
https://www.theglobaleconomy.com/Russia/current_account_dollars
●俄罗斯央行数据:https://cbr.ru/eng/statistics/macro_itm/external_sector/pb/bop-eval
●Trading Economics 公共数据:https://tradingeconomics.com/russia/current-account
●其它参考:
https://www.theglobaleconomy.com/Russia/current_account_dollars
https://www.ceicdata.com/en/indicator/russia/current-account-balance
https://www.moneycontrol.com/economic-calendar/rus-current-account/13515932
https://www.fxempire.com/macro/russian-federation/current-account

捐助公益研究
感谢阅读
董斌:南柯舟堆垒迭代在经济预测中的高数原理基础: CPI 月度同比序列——二范数尺度与增强预测模型公式清单
公式 1:月度时间索引映射公式
进行了什么计算:把原始数据中的“年份--月份”结构转换成一条连续月度时间序列,便于后续计算斜率、滚动项、季节偏差和二范数。
为什么这样计算: 二范数、AR 滚动项、斜率和置信区间都要求输入是一条统一排列的一维时间序列。
$$t = 12(y-y_0)+(m-1), \qquad x_t = \mathrm{CPI}_{y,m}, \qquad m=1,2,\ldots,12.$$
其中,$y$ 表示年份,$m$ 表示月份,$y_0=2009$,$x_t$ 表示第 $t$ 个月的 CPI 同比值。
公式 2:有效观察集定义公式
进行了什么计算: 定义哪些月份是真实参与建模的有效观察值。
为什么这样计算: 已经观测到的 2009--2025 年部分月度值可以参与统计;未来月份不能直接当成真实值,必须由模型补齐或预测。
$$\mathcal{T}_{\mathrm{obs}} = \{t \mid x_t \ \text{为真实已观测 CPI 同比值}\}.$$
公式 3:前溯零值隔离公式
$$x_t^{\ast}=\left\{\begin{array}{ll}\mathrm{NaN}, & t\in\mathcal{T}_{\mathrm{ban}}\land x_t=0, \\ x_t, & \text{otherwise}.\end{array}\right.$$
进行了什么计算:把禁止区中的硬性零值占位从统计样本中剔除。
为什么这样计算:零值占位不是经济含义上的 CPI 同比为零,而是数据缺失或管道填充造成的假信号。如果保留,会污染均值、标准差、二范数和斜率。
其中,禁止区时间索引集合定义为:
$$\mathcal{T}_{\mathrm{ban}} = \left\{ 12(y-y_0)+(m-1) \mid 1998\le y\le 2008,\ 1\le m\le 12 \right\}.$$
公式 4:年度均值公式
进行了什么计算:把每一年的 12 个月 CPI 同比清洗后值压缩成年度平均水平。
为什么这样计算:年度堆垒斜率需要先得到年度水平,再比较年度之间的变化,且必须基于隔离零值污染后的序列计算。
$$\bar{x}_y = \frac{1}{12} \sum_{m=1}^{12} x^{\ast}_{y,m}.$$
若某一年只有部分月份真实观测,则先记为:
$$\bar{x}_y^{\mathrm{obs}} = \frac{1}{|\mathcal{M}_y|} \sum_{m\in \mathcal{M}_y} x^{\ast}_{y,m},$$
其中 $\mathcal{M}_y$ 是该年已有真实观测月份集合。
公式 5:月度一阶变化率公式
进行了什么计算:计算 CPI 同比序列相邻月份之间的变化量。
为什么这样计算:CPI 同比本身不是普通线性状态量,因此不直接外推水平值,而先提取月度变化速度。
$$\Delta x_t = x_t-x_{t-1}.$$
公式 6:年度堆垒斜率公式
进行了什么计算:计算年度平均 CPI 同比的跨年变化。
为什么这样计算:年度堆垒斜率用于捕捉中长期趋势,例如通胀从低位修复、回落或重新上行。
$$g_y = \bar{x}_y-\bar{x}_{y-1}.$$
公式 7:指数衰减堆垒权重公式
进行了什么计算: 给近年的斜率更高权重,给较早年份更低权重。
为什么这样计算:CPI 预测对近年经济状态更敏感,特别是需求缺口、食品价格、能源价格和政策调控的近期变化。
权重采用从 $i=1$ 开始的指数衰减归一化形式。更稳的 KaTeX 写法如下:
$$\omega_i(\rho_s)=\frac{\exp[-\rho_s(i-1)]}{\sum_{j=1}^{L}\exp[-\rho_s(j-1)]},\qquad i=1,2,\ldots,L.$$
其中,$\rho_s\in[0,1]$ 为系统密度参数,$L$ 为参与堆垒的历史年数。
$$\sum_{i=1}^{L}\omega_i(\rho_s)=1.$$
其中分母正是所有层级指数权重的总和,所以归一化后必然满足:
$$\sum_{i=1}^{L}\omega_i(\rho_s)=\frac{\sum_{i=1}^{L}\exp\left(-\rho_s(i-1)\right)}{\sum_{j=1}^{L}\exp\left(-\rho_s(j-1)\right)}=1.$$
公式 8:年度堆垒斜率公式(合成)
进行了什么计算: 把最近 $L$ 年的年度斜率按指数权重合成为一个历史堆垒斜率。
为什么这样计算: 单一年份斜率对端点很敏感,堆垒加权可以降低单点噪声,同时保留近年趋势。
$$G_y^{\mathrm{stack}} = \sum_{i=1}^{L} \omega_i(\rho_s)\, g_{y-i+1}.$$
公式 9:上行斜率与下行斜率统计公式
进行了什么计算:分别统计过去十年中上行年份和下行年份的斜率特征。
为什么这样计算: CPI 存在拐点风险,不能只用一条线性斜率外推。上行斜率和下行斜率分开统计,可以识别通胀修复和回落的不同规律。
$$\mu_g^{+} = \frac{1}{|\mathcal{Y}^{+}|} \sum_{y\in\mathcal{Y}^{+}} g_y, \qquad \mathcal{Y}^{+} = \{y\mid g_y>0\},$$
$$\mu_g^{-} = \frac{1}{|\mathcal{Y}^{-}|} \sum_{y\in\mathcal{Y}^{-}} g_y, \qquad \mathcal{Y}^{-} = \{y\mid g_y<0\}.$$
注:若 $|\mathcal{Y}^{+}|=0$ 或 $|\mathcal{Y}^{-}|=0$,则对应均值由中位斜率、零值或人工设定的保守斜率替代,防止空集合除法报错。
公式 10:上行概率公式
进行了什么计算:计算过去十年中年度 CPI 平均值上行的频率。
为什么这样计算:未来路径不能只靠端点斜率,还要考虑历史上通胀进入上行状态的经验概率。加入极小常数可防止除零。
$$p^{+} = \frac{|\mathcal{Y}^{+}|} {|\mathcal{Y}^{+}|+|\mathcal{Y}^{-}|+\varepsilon}.$$
公式 11:状态修正年度斜率公式
进行了什么计算:将历史堆垒斜率、上行斜率、下行斜率和上行概率合成为未来年度斜率。
为什么这样计算:这样可以避免只用线性外推,同时让模型识别“近年已经出现上行斜率”的事实。
$$\widetilde{G}_{y+1} = \eta\,G_y^{\mathrm{stack}} + (1-\eta) \left[ p^{+}\mu_g^{+} + (1-p^{+})\mu_g^{-} \right].$$
其中,$\eta\in[0,1]$ 是堆垒斜率与历史状态概率之间的混合权重。
公式 12:历史季节偏差公式
进行了什么计算:计算每个月相对于当年均值的历史季节偏差。
为什么这样计算:CPI 同比受春节错位、食品价格、猪肉周期和能源价格影响,有明显月度形态。季节偏差用于恢复月度形态,而不是仅预测年度均值。
$$s_m = \operatorname{median}_{y\in\mathcal{Y}_{10}} \left( x_{y,m}-\bar{x}_y \right), \qquad m=1,2,\ldots,12.$$
其中,$\mathcal{Y}_{10}$ 表示最近十年样本年份。
公式 13:月度 AR 滚动项公式
进行了什么计算:利用最近几个月的 CPI 同比变化率,估计下一月的短期惯性,统一按年月索引定标。
为什么这样计算:CPI 同比具有短期粘性,食品、能源和政策因素的影响常常会连续几个月传导。
$$A_{y,m} = \sum_{k=1}^{p} \phi_k \Delta x_{t(y,m)-k+1}.$$
其中:
$$t(y,m) = 12(y-y_0)+(m-1).$$
$p$ 是 AR 滚动阶数,$\phi_1,\ldots,\phi_p$ 是由历史数据估计出的权重。
公式 14:外生因子同步扰动公式
进行了什么计算:把春节错位、食品价格、能源价格、货币条件和需求缺口纳入同月同步扰动。
$$\omega_i(\rho_s)=\frac{\exp\left(-\rho_s i\right)}{\sum_{j=1}^{L}\exp\left(-\rho_s j\right)},\quad i=1,2,\ldots,L.$$
其中,$\rho_s\in[0,1]$ 为系统密度参数,$L$ 为参与堆垒的历史年数。
为什么这样计算:这些因素会对 CPI 产生同频冲击,仅靠斜率和季节偏差容易低估拐点风险。
$$C_{y,m} = \beta_F F_{y,m} + \beta_E E_{y,m} + \beta_P P_{y,m} + \beta_D D_{y,m} + \beta_M M_{y,m}.$$
其中:
$$\begin{array}{ll}F_{y,m} & = \text{食品价格因子}, \\ E_{y,m} & = \text{能源价格因子}, \\ P_{y,m} & = \text{春节错位或政策调控因子}, \\ D_{y,m} & = \text{需求缺口因子}, \\ M_{y,m} & = \text{货币条件因子}.\end{array}$$
若没有这些外生变量的真实数据,则 $C_{y,m}$ 不应被强行估计,而应进入情景路径或残差置信区间。
公式 15:2025 年缺失月份补齐公式
进行了什么计算:先补齐 2025 年下半年缺失月份,使 2025 年成为完整年度样本。
为什么这样计算:如果 2025 年只有 6 个月数据,直接计算年度斜率会低估或扭曲 2025 年趋势,所以必须先补齐全年。
$$\widehat{x}_{2025,m} = \widehat{x}_{2025,m-1} + \alpha\frac{\widetilde{G}_{2025}}{12} + \beta A_{2025,m} + \gamma(s_m-s_{m-1}) + C_{2025,m}, \qquad m=7,\ldots,12.$$
公式 16:未来月份中路径预测公式
进行了什么计算:生成 2026--2028 年 CPI 月度同比的中性路径。
为什么这样计算:中性路径综合年度堆垒斜率、月度惯性、季节偏差和外生冲击,是比单纯线性外推更稳健的路径。
$$\widehat{x}^{\,\mathrm{mid}}_{y,m} = \widehat{x}_{y,m-1} + \alpha\frac{\widetilde{G}_{y}}{12} + \beta A_{y,m} + \gamma(s_m-s_{m-1}) + C_{y,m}.$$
为保证跨年平滑过渡,补充以下边界定义(当 $m=1$ 时连接上一年度 12 月):
$$\widehat{x}_{y,0} = \widehat{x}_{y-1,12}, \qquad s_0 = s_{12}.$$
其中,$y=2026,2027,2028$,$m=1,2,\ldots,12$。
公式 17:预测残差公式
进行了什么计算:计算模型历史拟合误差。
为什么这样计算: 未来预测不能只给确定值,必须用历史误差估计不确定性,且残差限定在真实观测期内,避免受预测值干扰。
$$e_t = x_t-\widehat{x}_t, \qquad t\in\mathcal{T}_{\mathrm{fit}}\subseteq\mathcal{T}_{\mathrm{obs}}.$$
公式 18:预测误差标准差公式
进行了什么计算:计算历史预测残差的标准差。
为什么这样计算:残差标准差用于构造低、中、高三组路径的置信区间,且仅基于拟合期内的样本计算。
$$\sigma_e = \sqrt{ \frac{1}{|\mathcal{T}_{\mathrm{fit}}|-1} \sum_{t\in\mathcal{T}_{\mathrm{fit}}} (e_t-\bar{e})^2 }.$$
公式 19:预测期不确定性扩张公式
进行了什么计算: 随着预测期变长,扩大未来预测的不确定性区间。
为什么这样计算:2028 年的不确定性应大于 2026 年,远期路径不能和近期路径使用同样窄的区间。
$$\sigma_h = \sigma_e\sqrt{h},$$
其中,$h$ 是距离最后一个真实观测月的预测步数。
公式 20:低、中、高三路径公式
进行了什么计算:在中性路径两侧生成低路径和高路径。
为什么这样计算:CPI 受食品、能源、政策和需求扰动影响较大,用三路径比单一路径更科学。
$$\omega_i(\rho_s)=\frac{\exp\left(-\rho_s(i-1)\right)}{\sum_{j=1}^{L}\exp\left(-\rho_s(j-1)\right)},\quad i=1,2,\ldots,L.$$
$$\sum_{i=1}^{L}\omega_i(\rho_s)=1.$$
通常可取:
$$z_{\alpha}=1.28 \quad \text{对应约 } 80\% \text{区间},$$
或:
$$z_{\alpha}=1.64 \quad \text{对应约 } 90\% \text{区间}.$$
公式 21:鲁棒标准化公式
进行了什么计算:把 CPI 序列转换成标准化残差序列。
为什么这样计算:二范数尺度通常不直接比较原始数值,而比较标准化后的整体偏离能量。
$$z_t = \frac{x_t-\operatorname{median}(x)} {1.4826\cdot \operatorname{MAD}(x)}.$$
其中:
$$\operatorname{MAD}(x) = \operatorname{median}\left( |x_t-\operatorname{median}(x)| \right).$$
公式 22:二范数公式
进行了什么计算:计算整条标准化 CPI 序列的总体波动能量。
为什么这样计算:二范数衡量的是序列整体偏离强度,数值越大,说明历史波动能量越集中或越强。
$$\lVert z\rVert_2 = \sqrt{ \sum_{t=1}^{N} z_t^2 }.$$
公式 23:二范数尺度近似公式
进行了什么计算: 用维度规模 $N$ 和标准差 $\sigma_z$ 近似估计二范数。
为什么这样计算:根据严格的恒等关系:
$$\lVert z\rVert_2 = \sqrt{N(\sigma_z^2+\bar{z}^2)}.$$
当标准化序列均值接近零(即 $\bar{z}\approx 0$)时,可以采用近似,这是高维尺度判断的核心:
$$\lVert z\rVert_2 \approx \sqrt{N}\,\sigma_z.$$
公式 24:二范数尺度差距公式
进行了什么计算:比较真实二范数与尺度近似值之间的差距。
为什么这样计算: 如果差距小,说明波动能量较均匀;如果差距大,说明序列中可能存在少数强冲击或结构性偏离。
$$D_{\mathrm{gap}} = \left| \lVert z\rVert_2 - \sqrt{N}\sigma_z \right|.$$
$$r_{\mathrm{gap}} = \frac{ D_{\mathrm{gap}} }{ \max(\lVert z\rVert_2,\varepsilon) }.$$
其中,$\varepsilon$ 是防止除零的小常数。
公式 25:年度输出还原公式
进行了什么计算:把预测出来的连续月度序列重新整理成原始字典格式。
为什么这样计算:用户输入数据是按年份组织的,最终输出也应保持同样格式,便于直接复制回 API 或 Python 代码。
$$\widehat{\mathrm{CPI}}_{y} = \left[ \widehat{x}_{y,1}, \widehat{x}_{y,2}, \ldots, \widehat{x}_{y,12} \right], \qquad y=2026,2027,2028.$$
公式26:量化控制矩阵公式
在“堆垒迭代因果关系论”量化模型中,双特征控制矩阵的底层驱动公式如下:
$$\text{动态斜率}=\text{基础斜率}\times\left(1+\alpha\cdot\Delta\text{Shibor}+\beta\cdot\Delta\text{Injection}\right)$$
其中:
- $\Delta\text{Shibor}$ 为 3 个月期同业拆借利率偏离度,即价格信号,且 $\alpha<0$。
- $\Delta\text{Injection}$ 为央行流动性净投放规模偏离度,即水量信号,且 $\beta>0$。
等同于下列英文公式:量化控制矩阵公式
$$\text{Dynamic Slope}=\text{Basic Slope}\times\left(1+\alpha\cdot\Delta\text{Shibor}+\beta\cdot\Delta\text{Injection}\right)$$
核心解释
二范数是什么?
二范数是一个向量整体强度的度量。若一条标准化 CPI 序列写成:
$$z=(z_1,z_2,\ldots,z_N),$$
则它的二范数为:
$$\lVert z\rVert_2 = \sqrt{z_1^2+z_2^2+\cdots+z_N^2}.$$
●它衡量的是整条序列的总体波动能量(实际上总体波动能量包含由历史推进的趋势),而不是某一个月的涨跌。
二范数尺度近似是什么?
基于恒等分布模型:
$$\lVert z\rVert_2 = \sqrt{N(\sigma_z^2+\bar{z}^2)}$$
当序列长度为 $N$,标准化序列标准差为 $\sigma_z$ 且均值趋近于 $0$ 时,可以用:
$$\lVert z\rVert_2 \approx \sqrt{N}\,\sigma_z$$
来近似二范数规模。
这说明二范数会随着样本维度 $N$ 的平方根扩大,也会随着波动强度 $\sigma_z$ 扩大。
为什么二范数不能“直接”去当预测模型?
使用二范数回答的是:
$$\text{这条历史序列整体波动能量有多强?}$$
而按照 “AR 堆垒斜率趋势及概率框架”回答的是:
$$\text{未来 CPI 的方向性倾向、路径区间和不确定性如何?}$$
所以在预测 2026--2028 年 CPI 时,需要把二范数与年度堆垒斜率、月度 AR 滚动项、季节偏差、外生因子和置信区间结合使用,以获得完整的量化视角。
●南柯舟堆垒效应系统公式组
董斌
建议 安装XeLaTeX 宏包:`amsmath`、`amssymb`、`mathtools`、`xeCJK`
1. 堆垒效应公式
$$P_{t+1}=P_t\cdot\exp\left[\left(\mu-\frac{1}{2}\sigma_t^2\right)\Delta t+\sigma_t\sqrt{\Delta t}\cdot\epsilon_t\right]$$
2. 因果演进方程
在特定状态 $S_t$ 下,因果演进方程为:
$$r_t=\mu(S_t)+\sum_{k=1}^{n}\phi_k(S_t)r_{t-k}+\sigma(S_t)\epsilon_t$$
3. 因果触发函数
$$T(S_t)=\mathbb{I}\left\{\frac{\Delta\text{Leverage}_t}{\sigma_t}>\gamma\cdot\frac{\text{Volume}_t}{\text{Volume}_{t-1}}\right\}$$
其中,$T(S_t)$ 表示状态 $S_t$ 下的触发函数,$\mathbb{I}\{\cdot\}$ 表示指示函数。
4. 状态转移概率矩阵
$$P = \begin{bmatrix} p_{11} & p_{12} & p_{13} \\ p_{21} & p_{22} & p_{23} \\ p_{31} & p_{32} & p_{33} \end{bmatrix} \approx \begin{bmatrix} 0.85 & 0.10 & 0.05 \\ 0.20 & 0.60 & 0.20 \\ 0.15 & 0.05 & 0.80 \end{bmatrix}$$
5. 模型解释
在这一框架中,状态跃迁不仅是概率性的,也受到触发函数 $T(S_t)$ 的动态控制。该结构可以用于表达“堆垒迭代因果关系”中的状态转换、冲击放大与路径依赖机制。
6.中国经济七状态基准点数与 S7 二级对称基准点数公式
七状态基准点数与 S7 二级对称基准点数公式
公式一:第 $i$ 个状态 $S_i$ 内部第 $k$ 组首尾对称配对中点
$$m_{i,k}=\frac{x_{i,\mathrm{left},k}w_{i,\mathrm{left},k}+x_{i,\mathrm{right},k}w_{i,\mathrm{right},k}}{w_{i,\mathrm{left},k}+w_{i,\mathrm{right},k}}$$
公式二:第 $i$ 个状态 $S_i$ 的一级状态基准点数
$$B_{S_i}^{(1)}=\frac{\sum_{k=1}^{K_i}m_{i,k}W_{i,k}}{\sum_{k=1}^{K_i}W_{i,k}},\qquad W_{i,k}=w_{i,\mathrm{left},k}+w_{i,\mathrm{right},k}$$
公式三:S7 的七状态二级输入点列
$$\mathcal{C}_{S7}=\left\{\left(B_{S_1}^{(1)},\lambda_1\right),\left(B_{S_2}^{(1)},\lambda_2\right),\left(B_{S_3}^{(1)},\lambda_3\right),\left(B_{S_4}^{(1)},\lambda_4\right),\left(B_{S_5}^{(1)},\lambda_5\right),\left(B_{S_6}^{(1)},\lambda_6\right),\left(B_{S_7}^{(1)},\lambda_7\right)\right\}$$
公式四:S7 二级对称配对集合
$$\mathcal{P}_{S7}^{(2)}=\{(1,7),(2,6),(3,5),(4,4)\}$$
公式五:S7 二级对称配对中点
$$M_{a,b}^{(2)}=\frac{\lambda_a B_{S_a}^{(1)}+\lambda_b B_{S_b}^{(1)}}{\lambda_a+\lambda_b}\quad\text{当 }a\lt b,\qquad M_{a,a}^{(2)}=B_{S_a}^{(1)}\quad\text{当 }a=b$$
公式六:S7 二级对称配对权重
$$\Omega_{a,b}^{(2)}=\lambda_a+\lambda_b\quad\text{当 }a\lt b,\qquad \Omega_{a,a}^{(2)}=\lambda_a\quad\text{当 }a=b$$
公式七:S7 最终排名第一基准点数
$$B_{S7}^{\mathrm{final}}=\frac{\sum_{(a,b)\in\mathcal{P}_{S7}^{(2)}}M_{a,b}^{(2)}\Omega_{a,b}^{(2)}}{\sum_{(a,b)\in\mathcal{P}_{S7}^{(2)}}\Omega_{a,b}^{(2)}}$$
公式八:目标日期状态归属函数
$$S^\ast(d)=\left\{\begin{array}{ll}S_1, & d\in[t_0,\text{2005-12-31}], \\ S_2, & d\in[\text{2006-01-01},\text{2014-10-31}], \\ S_3, & d\in[\text{2014-11-01},\text{2015-09-30}], \\ S_4, & d\in[\text{2015-10-01},\text{2017-12-31}], \\ S_5, & d\in[\text{2018-01-01},\text{2019-12-31}], \\ S_6, & d\in[\text{2020-01-01},\text{2020-11-30}], \\ S_7, & d\geq\text{2020-12-01}.\end{array}\right.$$
公式九:目标状态基准点数读取规则
$$B_{\mathrm{rank1}}(d)=\left\{\begin{array}{ll}B_{S_i}^{(1)}, & S^\ast(d)=S_i,\ i\in\{1,2,3,4,5,6\}, \\ B_{S7}^{\mathrm{final}}, & S^\ast(d)=S_7.\end{array}\right.$$
公式十:七状态排名第一硬门控修正
$$\begin{array}{l}u(d)=\eta\left(B_{\mathrm{rank1}}(d)-\widehat{y}_{\mathrm{base}}(d)\right),\qquad \eta=0.18,\quad C=35, \\ A_{\mathrm{rank1}}(d)=\left\{\begin{array}{ll}-C, & u(d)<-C, \\ u(d), & -C\leq u(d)\leq C, \\ C, & u(d)>C.\end{array}\right.\end{array}$$
公式十一:最终预测点数
$$\widehat{y}_{\mathrm{final}}(d)=\widehat{y}_{\mathrm{base}}(d)+A_{\mathrm{rank1}}(d)+A_{\mathrm{2yr}}(d)+R_{\mathrm{short}}(d)$$
其中,$S_i$ 表示第 $i$ 个历史制度状态,$x_{i,\mathrm{left},k}$ 与 $x_{i,\mathrm{right},k}$ 分别表示状态 $S_i$ 内第 $k$ 组首尾对称样本的左侧点数与右侧点数,$w_{i,\mathrm{left},k}$ 与 $w_{i,\mathrm{right},k}$ 分别表示左右样本权重,$m_{i,k}$ 表示该组对称配对中点,$W_{i,k}$ 表示该组对称配对总权重,$B_{S_i}^{(1)}$ 表示状态 $S_i$ 的一级状态基准点数,$\lambda_i$ 表示状态 $S_i$ 在 S7 二级基准生成中的状态权重,$M_{a,b}^{(2)}$ 表示 S7 二级对称配对中点,$\Omega_{a,b}^{(2)}$ 表示 S7 二级对称配对权重,$B_{S7}^{\mathrm{final}}$ 表示由 $S_1$ 至 $S_7$ 七个状态级基准点数共同二级对称生成的 S7 最终基准点数,$S^\ast(d)$ 表示目标日期 $d$ 的状态归属,$B_{\mathrm{rank1}}(d)$ 表示目标日期读取到的排名第一状态基准点数,$\widehat{y}_{\mathrm{base}}(d)$ 表示基础预测点数,$A_{\mathrm{rank1}}(d)$ 表示七状态排名第一硬门控修正,$A_{\mathrm{2yr}}(d)$ 表示两年弱信号函数修正,$R_{\mathrm{short}}(d)$ 表示短期残差纠偏项,$\widehat{y}_{\mathrm{final}}(d)$ 表示最终预测点数。
●弱信号捕捉研究
董斌
从《南柯舟堆垒迭代数学模型》审计报告中,筛选出在数据学上进行弱信号挖掘、捕捉、动力学关联以及噪声控制直接相关的核心数学公式。以下是提取并纯化后的代码,可以直接使用。
公式 1:滞后动态关联机制
$$R_{ij}(t,\tau)=\Phi\!\left(\Delta x_i(t),\Delta x_j(t+\tau),\rho_s,\lambda_d\right)$$
公式 2:弱信号的统计边界
$$\lVert z\rVert_2\approx\sqrt{N}\,\sigma_z$$
公式 3:多层级叠加态弱信号提取
$$\Psi_n(x)=\sum_{i=1}^{L}\omega_i(\rho_s)\cdot I_i^{\,n}(x_0)$$
公式 4:层级自适应指数权重分配
$$\omega_i(\rho_s)=\frac{\exp(-\rho_s i)}{\sum_{j=1}^{L}\exp(-\rho_s j)}$$
公式 5:弱信号的非线性迭代演化与多层数据叠加融合
$$S\!\left[\{x_{n,i}\}\right]=\sum_{i=1}^{L}\omega_i(\rho_s)\cdot x_{n,i}$$
公式 6:伴随多层噪声扰动的动态系统弱信号捕捉演化步进
$$x_{n+1,i}=f_i(x_{n,i})+\sigma(\rho_s)\left[\nabla\Psi_n\right]+\epsilon_i$$
公式 7:引入阻尼记忆惯性项的弱信号渐进捕捉方程
$$x_{n+1}=\lambda_d x_n+(1-\lambda_d)\left(S_n+\sigma(\rho_s)\nabla S_n\right)$$
公式 8:弱信号调制系数
$$\sigma(\rho_s)=1-\rho_s$$
公式 9:数据层内背景噪声项的随机分布模型
$$\epsilon_i\sim\mathcal{N}(0,\sigma_{\epsilon}^{2})$$
公式 10:基于子空间或降维映射的层级弱信号迭代捕捉
$$S_{B_k}(x)=\sum_{i=1}^{L}\omega_i(\rho_s)\,g_i\!\left(A_{B_k}x\right)$$
在金融背景下,经典双稳态随机共振模型可通过以下 Langevin 方程描述:
$$ \frac{dx}{dt} = a x - b x^3 + A \cdot f(t) + \sqrt{2D} \, \xi(t) $$
其中: - $x$ 表示金融状态变量(如价格偏差、预期收益率或市场情绪指数); - $a > 0$、$b > 0$ 为双稳态势阱参数; - $A \cdot f(t)$ 为周期性或外部弱信号(如宏观因子、政策信号); - $D$ 为噪声强度(代表市场随机波动);
$\xi(t)$ 为标准高斯白噪声,满足 $\langle \xi(t) \xi(s) \rangle = \delta(t-s)$。
